Claude Managed Agents are a useful signal for where the AI stack is going. Anthropic describes Managed Agents as pre-built, configurable agent infrastructure where Claude can read files, run commands, browse the web, execute code, and connect to MCP servers without the developer building the agent loop, sandbox, or tool execution layer from scratch (Claude API Docs). In the quickstart, the runtime provisions a container, runs the agent loop, executes file writes, bash commands, and tool calls inside the container, streams events, and then goes idle when the session is done (Claude API Docs).
That should tell us something. Even agents are moving from “everyone builds the loop themselves” to managed primitives. The thing that looks magical on the surface is actually infrastructure underneath: sessions, containers, tools, files, events, permissions, and state.
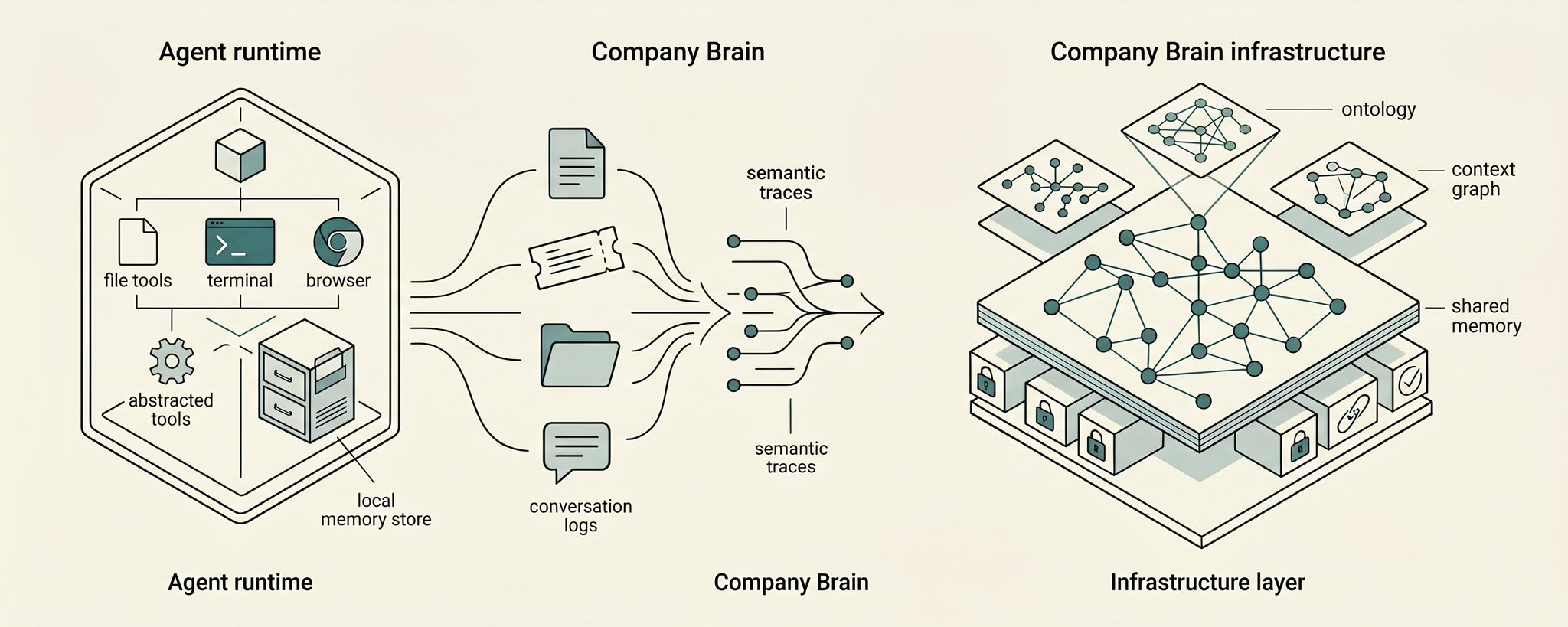
I think the next layer is Company Brain. I do not mean a chatbot for the company or a knowledge base with better search. I mean the infrastructure layer that lets every app, agent, workflow, and human decision surface act from the same company state.
This is what we are building at Sentra. The deeper I get into the problem, the more convinced I am that what people are calling “agent memory” is really the beginning of Company Brain. This piece follows the earlier series: Part 1, Part 2, Part 3, Part 4, Part 5, Part 6, and Part 7.
Claude is making a telling move here. Its docs describe Memory as a way for Claude to store and retrieve information across conversations, build knowledge bases over time, maintain project context, and learn from past interactions (Claude API Docs). The Managed Agents memory docs describe memory stores as workspace-scoped collections of text documents that can be attached to a session, mounted under /mnt/memory/, and read or written by the agent with normal file tools (Claude API Docs).
That direction is right. But a knowledge base is not the same thing as Company Brain. A knowledge base stores useful information. Company Brain maintains operational state. It has to know what happened, why it mattered, who saw it, which source is trusted, what action followed, which permission applies, and what the company should learn from the outcome.
That is not storage. It is infrastructure.
The App Mistake
The first instinct of any serious company will be to build its own Company Brain. That instinct is understandable. The data is sensitive, the workflows are strange, the permissions are messy, and the vocabulary is company-specific. No outside system can simply walk in and understand how the company works.
All true. But it still does not mean every company should build the substrate from scratch. This is where vibe coding creates a false sense of confidence. Vibe coding is real, and I use these tools constantly. A small team can prototype an internal AI app faster than ever: connect Slack, Drive, Jira, Salesforce, GitHub, and meeting transcripts; create embeddings; add a graph; put a chat box on top. Someone asks “what happened with this customer?” and the answer is good enough to make everyone lean forward.
That demo is seductive because it feels like the thing exists. But infrastructure is not judged by the first answer. It is judged by what happens after six months of writes, permission changes, stale documents, duplicate customers, renamed projects, conflicting sources, and agents acting at the same time.
An app can be useful while being messy. Infrastructure has to survive being depended on.
Markdown Brains Are Prototypes
The recent markdown-brain movement is directionally right. Garry Tan described GBrain as an open-source setup for agents to have recall over 10,000+ markdown files (Garry Tan). Andrej Karpathy’s LLM Wiki describes a pattern where raw sources are compiled into an LLM-generated markdown wiki, with entity pages, concept pages, cross-references, citations, health checks, and answers that can be filed back into the wiki (Karpathy).
I like these ideas. They show that the community is converging on something real: durable context should be readable, editable, versionable, and close to files. Markdown is a great medium for personal or small-team brain systems because humans can inspect it, agents can write it, Git can track it, and the whole thing stays portable.
The scaling boundary appears when the brain becomes organizational. A personal markdown brain usually has one owner, one trust boundary, one tolerance for messiness, and one final arbiter. If the model writes a bad summary, you can fix it. If two pages contradict each other, you decide which one to believe.
Companies do not get that simplicity. They have multiple writers, multiple readers, inherited permissions, regulated data, stale sources, conflicting teams, and agents that may act on what they read. A markdown file can hold information. It does not, by itself, decide who can see it, which ontology applies, whether it is stale, whether it is fact or interpretation, or what happens when two agents update related state at the same time.
That is why the file metaphor is useful but incomplete. Files can be the source. Company Brain is the substrate that makes files, traces, semantics, ontology, permissions, and actions work together.
The AWS Lesson
Cloud infrastructure already taught us this pattern. Before AWS became obvious, many companies believed infrastructure was too central to depend on someone else for. They had servers, infra teams, security needs, compliance requirements, and custom workloads. They were not wrong about the importance of infrastructure. They were wrong about which parts were differentiated.
AWS describes cloud computing as on-demand delivery of IT resources over the internet, where companies can access services like compute, storage, and databases instead of buying, owning, and maintaining physical data centers and servers (AWS). Cloud did not make infrastructure disappear. It made the primitive reliable enough that companies could build higher up the stack.
Company Brain has the same shape. Every company needs its own ontology, policy, permission model, and judgment. But the substrate that turns work into durable, inspectable company state is not something every company should rebuild from zero.
The mistake is thinking the choice is between a generic brain and a fully internal one. The better architecture is shared infrastructure with company-specific ontology.
Tool Access Is Not Company Brain
MCP is a major step in the current AI stack. The Model Context Protocol documentation describes MCP as an open-source standard for connecting AI applications to external systems, including data sources, tools, and workflows (Model Context Protocol). Anthropic introduced MCP as an open standard for connecting AI assistants to the systems where data lives, including content repositories, business tools, and development environments (Anthropic).
Agents need tools. They need to read docs, search Slack, query databases, inspect tickets, call APIs, and write back into systems of record. Tool access will be part of every serious enterprise agent stack.
But tool access is not Company Brain. There is a trap here. A company connects agents to MCP servers, lets the agent search a few systems, fetch some documents, summarize the results, and calls that the brain. It will demo well because the agent can now look things up. But the agent is still reconstructing the company every time it acts.
That is query-time context. The agent starts a task, calls tools, searches systems, pulls documents, reads tickets, checks transcripts, and assembles context on the fly. It feels flexible. It is also slow, expensive, hard to verify, and easy to miss the thing that matters.
Company Brain should work differently. The context graph should already exist as maintained state. Meetings, messages, tickets, docs, customer calls, decisions, and actions should update the brain as work happens. Then, when an agent needs to act, it is not discovering the company from scratch. It is operating from the company’s current state, with sources and permissions attached.
The Hard Part Is State
Reading is hard enough. Writing is where the internal build turns into infrastructure. Claude’s memory tool docs describe a file-based directory where Claude can create, read, update, delete, and rename files, with the application executing the operations client-side (Claude API Docs). The same docs say developers should restrict memory operations to the /memories directory and implement path traversal protection by validating paths and rejecting traversal patterns like ../ (Claude API Docs).
Those details are the beginning of the infrastructure problem. Now imagine a company where multiple agents and humans are writing into the same brain. A support agent updates a customer risk. A sales agent writes a follow-up. A product agent changes the status of a feature request. A human edits the source doc. A Slack thread contradicts yesterday’s summary.
Who wins when two agents write to the same state? What gets versioned? What gets marked stale? What happens if an agent writes a wrong interpretation that another agent later reads as fact? What if a user can see the ticket but not the customer call that explains it?
This is why “we’ll just store notes” stops working. Company Brain needs concurrency control, provenance, permission propagation, ontology binding, action traces, evals, deletion policy, and conflict handling. Those are not features you sprinkle on after the demo. They are the reason the system can be trusted.
What Sentra Is Building
The point is not that companies should outsource their understanding of themselves. Companies should own the things that express how they work: ontology, permissions, trusted sources, workflows, and judgment.
Sentra is building the substrate underneath that ownership. Files remain sources. Semantics extracts what is inside. Ontology applies perspective. The graph maintains traces across artifacts, interactions, decisions, and actions. Permissions decide who can see what. Evals tell us whether agents actually had the right context before they acted.
This is why Company Brain should be infrastructure, not an app. Apps sit on top: CEO surface, manager surface, IC surface, support agent, sales agent, engineering agent, customer follow-up workflow, escalation workflow, planning workflow. The same underlying company state should serve all of them through different lenses.
The companies that win will not be the ones with the most internal AI demos. They will be the ones that turn work into company state quickly enough for humans and agents to act from it. That does not mean every company has to build the substrate.
Own the ontology. Own the policy. Own the judgment. But do not confuse Company Brain with another app. It is the infra layer the apps will sit on.
Part 1: Why most companies have date but no memory
Part 2: Factual Memory
Part 3: Interaction Memory
Part 4: Action Memory
Part 5: Memory Is State, Not a Service
Part 6: Lessons From Building A Company Brain
Part 7: Brain Needs Semantic And Ontology
At Sentra, where we are building what can be only described as a "company brain", a shared intelligence/memory layer that sits on all communication channels, knowledge bases, action and agent traces to understand how everyone in an organization actually works as well as how work actually gets done, constructing a living world model of the entire company in near real time.