At some point every new primitive becomes a bill. Cloud did it about a decade ago: compute, storage, bandwidth, logs, data warehouses, GPU hours. Teams learned, usually the hard way, that infrastructure usage can grow faster than product value. Tokens are now entering that category.
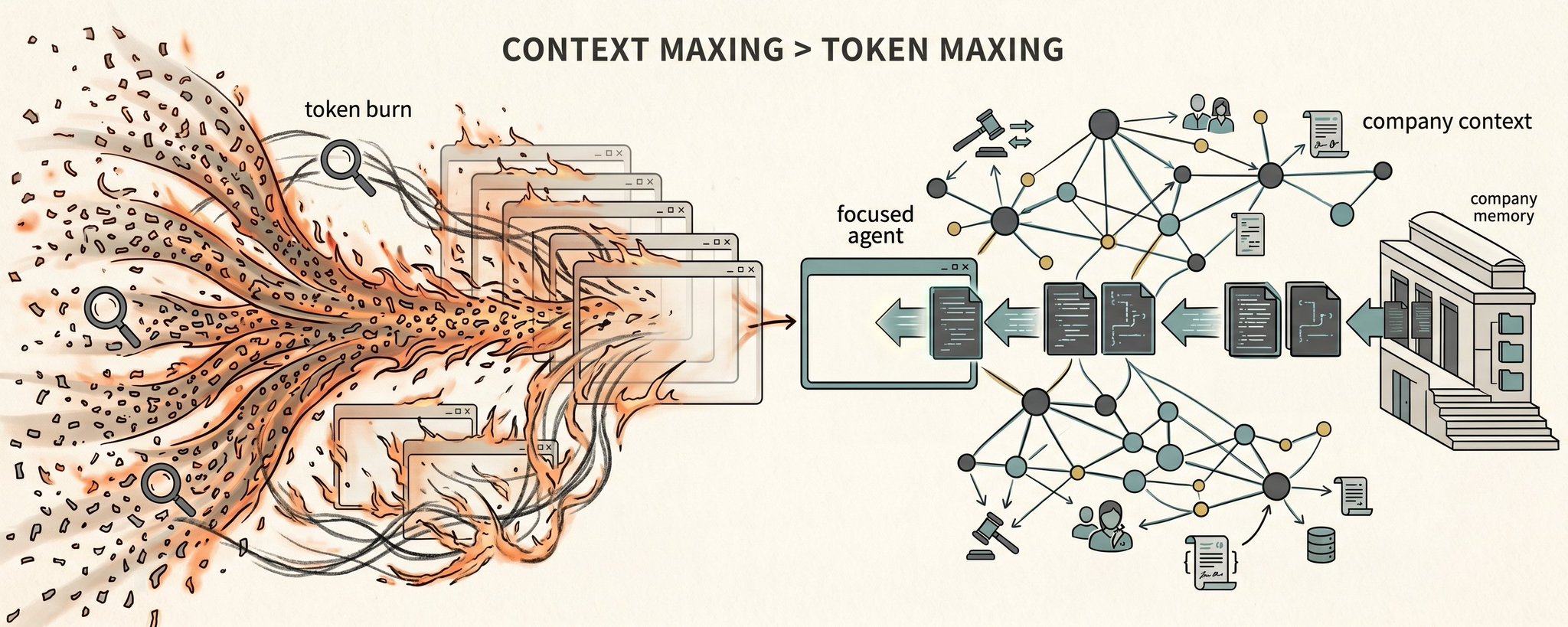
The first instinct will be to manage token spend the way companies manage any other cost. Set limits, build dashboards, ask teams to justify usage. Some of that will be necessary. But the more interesting question comes before budgeting: how much relevant context does the model get before it spends those tokens? Tokenmaxxing is maximizing AI activity. Contextmaxxing is maximizing relevant context per AI action.
The recent Uber story landed so hard for exactly this reason. Uber’s CTO reportedly said the company had already exhausted its AI budget just months into 2026 after usage of AI coding tools, especially Claude Code, exceeded internal expectations, leaving the company “back to the drawing board” on budgeting (Yahoo Finance). I do not read that as an Uber-specific failure. I read it as an early glimpse of the next enterprise cost curve.
Engineering is simply where the bill became visible first. Coding agents run for long stretches, inspect large codebases, edit files, test, review, retry, and sometimes spawn other agents. The same pattern will move into sales, support, finance, legal, customer success, recruiting, operations, and every workflow where agents start doing actual work.
The phrase for this is already here: tokenmaxxing. Built In defines tokenmaxxing as maximizing AI usage by consuming as many tokens as possible with autonomous agents, especially around tools like Claude Code and Codex (Built In). TechCrunch made the cleaner critique: token budgets measure input, not output, and treating token consumption as productivity is a strange way to measure work (TechCrunch).
I partly agree. Burning tokens is not the same as creating value. Still, token maxing is not stupid. It is the first rational response to useful AI. If an engineer can ship faster by running Claude Code, they will run Claude Code. If a support agent can resolve more tickets with AI, the company will push more tickets through AI. Airbnb has said its AI customer support agent resolves 40 percent of issues without human escalation, and Brian Chesky has described AI agents as giving the company more software-building capacity (Benzinga).
So I do not think the useful answer is “use fewer tokens.” That feels like telling a company in 2012 to use less cloud. Before cutting usage, ask what the tokens are buying.
A good run burns tokens on reasoning, writing, testing, review, and verification. A bad run burns tokens reconstructing context the organization already has. The model reads the codebase to understand why a migration exists. It searches tickets to find the customer constraint. It reads Slack to reconstruct the argument. It scans docs to discover the decision. It rereads the same transcript another agent read yesterday, then another agent does the same thing tomorrow.
That is token spend pretending to be intelligence. The model is not getting smarter in that loop. It is paying, over and over, to rebuild the missing state around the task. This is the limit of token maxing: you can buy more attempts, but you cannot brute-force your way around bad context forever.
Contextmaxxing starts from a different place. Instead of asking how much AI can be used, it asks how much of the right context can be put in front of the AI before it acts.
This matters because the value of an AI system is bounded by the quality of the context it receives. A decent agent with great context will usually beat a great agent with stale, partial, or wrong context. Inside companies, the hard part is rarely general reasoning. The hard part is knowing the current state of the organization.
Who owns the decision? What was promised to the customer? Which approach already failed? Which document is stale? Which meeting changed the plan? Which ticket contradicts the roadmap? Which support issue is now a renewal risk? Which code path exists because of a customer constraint nobody remembers? More tokens can help the model search for those answers. Better memory gives the model those answers before the search begins.
Contextmaxxing does not mean stuffing the largest possible prompt. That is just token maxing wearing a different costume. Context maxing means maximizing relevant, permissioned, evidence-backed context per AI action.
The word relevant matters. The right context is not everything. It is the prior decisions, constraints, owners, failed attempts, open questions, promises, contradictions, and source evidence that matter for the task at hand. Sometimes that is 500 tokens. Sometimes it is 5,000. Sometimes it is a graph lookup, a timeline, a customer trace, a decision trace, or a compact state object the agent can reason against.
Memory becomes economic infrastructure in this world. Without it, every agent starts from zero. It burns tokens asking the company who it is, what it knows, what it decided, and why the current task matters. With memory, the agent starts from state. It can spend tokens on judgment, execution, and verification rather than rediscovery.
This is another practical outcome of building our Sentra’s semantic file system the way we did. We were not trying to create a bigger prompt. We were trying to connect the interactions, documents, tickets, meetings, code, customer conversations, and actions of the company into a semantic layer that can produce the right context pack for the task. In early workflows, we have seen context-token usage fall by 50 to 98 percent for similar tasks. In some cases, the relevant context can be represented in hundreds of tokens instead of tens of thousands. I do not care about compression for its own sake. The agent should not spend expensive cognition remembering what the company already knows.
The recent wave of file-based memory systems matters for the same reason. Andrej Karpathy’s LLM Wiki argues that instead of retrieving raw documents at query time, an LLM should incrementally build and maintain a persistent wiki that compiles knowledge over time (Karpathy Gist). Garry Tan’s GStack describes GBrain as a persistent knowledge base for AI agents, a memory the agent keeps across sessions (Garry Tan GitHub). The broader second-brain world has been circling the same intuition for years: Obsidian, for example, is built around local markdown notes, links between notes, and graph views that help people see relationships in their own knowledge (Obsidian).
These patterns are excellent for individuals. A founder, researcher, or engineer can maintain a personal vault and get a huge amount of value from it. Extending that pattern to an enterprise is a different class of problem. The memory is no longer one person’s private context. It has to be shared across the organization, connected to live systems, permissioned by role, grounded in sources, updated as work changes, and safe for agents to read from and write back into. That is the layer we have been solving for with Sentra’s Company Brain (EGI) work over the last year.
Karpathy, Garry Tan, and the second-brain community are coming at the problem from practice. Use agents enough, and you feel the pain. Query-time retrieval keeps making the model re-derive what should have been compiled already. The enterprise version keeps the same insight, but raises the bar: memory has to become organizational infrastructure, not one person’s folder of notes.
We came to the same conclusion from a different direction. In “The Geometry of Forgetting,” we argued that forgetting can emerge from the geometry of similarity-based retrieval itself, not merely from biological hardware (arXiv). In “The Price of Meaning,” we argued that semantic memory systems face a structural tradeoff: organizing by meaning enables generalization, but it also creates interference, forgetting, and false recall (arXiv).
Those ideas point to the same architecture: RAG at query time is not enough. Memory has to be compiled, structured, maintained, permissioned, and made available before the agent acts. The irony is that context windows are getting larger at the same time this is becoming more urgent. People assume larger context windows solve the problem. They do not. They make it easier to dump more irrelevant material into the model. The bottleneck moves from “can I fit it?” to “what belongs here?”
Cloud taught us that cheaper compute does not remove spend. It creates more usage. The same will happen with tokens. Even if token prices fall, agent usage will expand faster. The way out is not smaller AI. It is better context discipline.
The next useful metric is not tokens used. It is useful context per token or verified outcome/work per token. The companies that learn this will not simply ask employees to use more AI. They will build systems that make every AI action start closer to the truth. Token maxing was the first phase of AI-native work. It proved people will spend aggressively when AI is useful. Context maxing is the next phase. It asks whether those tokens are pointed at the right version of reality.
The winners will not be the companies that use the most tokens. They will be the companies that waste the fewest tokens remembering what they already know.
At Sentra, where we are building what can be only described as a "company brain", a shared intelligence/memory layer that sits on all communication channels, knowledge bases, action and agent traces to understand how everyone in an organization actually works as well as how work actually gets done, constructing a living world model of the entire company in near real time.