TL;DR
Memory systems for LLMs forget EXACTLY like humans, reproducing the exact numbers from some of the most replicated experiments in clinical psychology.
For the last several months, we have been exploring a single observation: learned representations concentrate their variance in roughly 3 to 10% of their nominal dimensions. That concentration governs compression, attention, and, it turns out, memory itself.
Embedding models that claim to be 384 to 1,024-dimensional actually concentrate their variance in ~16 effective dimensions. This makes them vulnerable to the same interference that causes human forgetting.
Power-law forgetting observed in humans (the Ebbinghaus curve) emerges from competition between memories, not from decay over time. Remove the competitors and the forgetting exponent drops fifty-fold.
False memories require no engineering. Raw cosine similarity on unmodified pre-trained embeddings reproduces the classic false memory rate (0.583 vs human ~0.55) with zero parameter tuning.
The implication: forgetting and false memory are not bugs of biological hardware. They are features of any system that organizes information by meaning and retrieves it by proximity.
For the last several months, we have been studying a single phenomenon: the spectral concentration of learned representations. Across every system we have examined, from transformer attention heads to production embedding models to (based on published neural recordings) biological cortex, the pattern is the same. The nominal dimensionality is high: 128, 384, 768, 1,024. The effective dimensionality is low: roughly 3 to 4% of the nominal space carries meaningful variance. The rest is noise, or close to it.
We started by asking what this concentration means for compression, and the answer was SpectralQuant, which used the spectral gap in KV cache key vectors (d_eff ≈ 4 out of 128) to beat Google's provably near-optimal TurboQuant by 18.6% while simultaneously improving reconstruction quality. That work showed us the opportunity side of spectral concentration: it tells you where to put your bits.
But we kept asking: what else does this geometry control? The answer, it turns out, is memory itself. Not GPU memory. Human memory. The kind you use to remember your mother's phone number, the kind that fails when you walk into a room and forget why you are there, the kind that sometimes convinces you something happened when it did not.
We found that embedding spaces, subjected to noise, interference, and temporal degradation, reproduce the quantitative signatures of human memory with no phenomenon-specific engineering. Power-law forgetting, false memories, tip-of-tongue states, spacing effects. All of them emerge from the geometry of high-dimensional similarity-based retrieval. The same geometry we had been studying in transformers.
The boundary between biological and artificial memory is thinner than anyone assumed.
The thread that connects everything
Here is the connection that makes this more than a coincidence.
SpectralQuant measured the participation ratio of KV cache key vectors in transformer attention heads: d_eff ≈ 4 out of 128 dimensions, or about 3.1% of the nominal space. We exploited that concentration for compression, allocating bits where the signal was and skipping error correction where it was not. In this new paper, we measured the participation ratio of production embedding models, the models that power every RAG system, every vector database, every semantic search engine. MiniLM (nominally 384 dimensions) has d_eff = 15.7. BGE-base (768 dimensions) has d_eff = 16.6. BGE-large (1,024 dimensions) has d_eff = 16.3. Despite a nearly 3x range in nominal dimensionality, all three models concentrate their variance in roughly 16 effective dimensions. Only 17 to 18 principal components are needed for 95% explained variance, regardless of how many dimensions the model advertises.
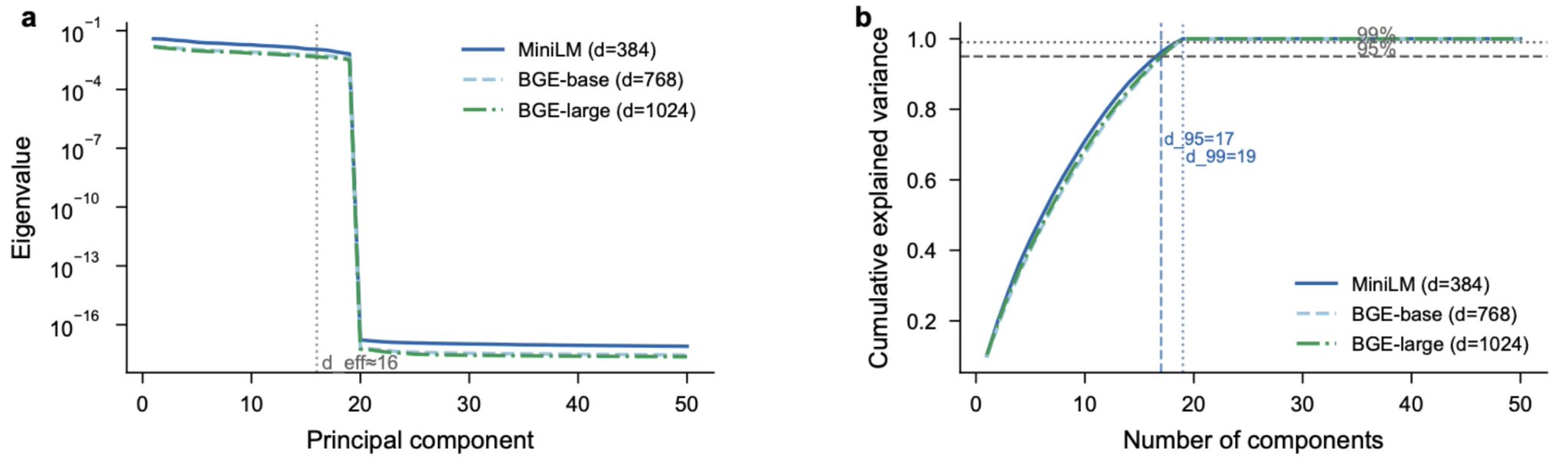
The dimensionality illusion. Despite nominal dimensionalities of 384, 768, and 1,024, all three production embedding models concentrate their variance in approximately 16 effective dimensions (left). Only 17 to 18 principal components are needed for 95% explained variance regardless of advertised dimensionality (right). A model that claims to be 1,024-dimensional but concentrates its variance in 16 is not providing 1,024 dimensions of protection against interference. It is providing 16.
This is the same phenomenon we found in the KV cache, showing up in a completely different part of the stack. In SpectralQuant, low effective dimensionality was an opportunity: it told us where to save bits. In memory systems, low effective dimensionality is a vulnerability: it is what makes memories interfere with each other, what causes forgetting, and what produces false recall. Same math. Opposite implications.
And here is where it gets strange. Cortical representations in the human brain are estimated to operate at effective dimensionalities of 100 to 500, based on neural recordings. That places biological memory right at the transition zone where interference becomes non-negligible but not catastrophic. The brain is not badly designed. It is operating at a dimensionality where interference is the price of admission for the computational benefits that moderate-dimensional codes provide.
What makes us forget
Every student of psychology learns the Ebbinghaus forgetting curve: memory decays as a power law with time. First documented in 1885, replicated across dozens of paradigms since. The standard explanation points to biology: the brain does its best, but evolution left us with hardware that leaks. Two theories have competed for over a century about the mechanism. Decay theories say memory traces fade with time. Interference theories say they get crowded out by competitors.
We tested both. We encoded 1,000 facts spanning 30 simulated days and applied temporal decay to retrieval scores, then measured whether forgetting looked like the human curve.
The critical test: does the forgetting exponent depend on the decay function or on the number of competing memories?
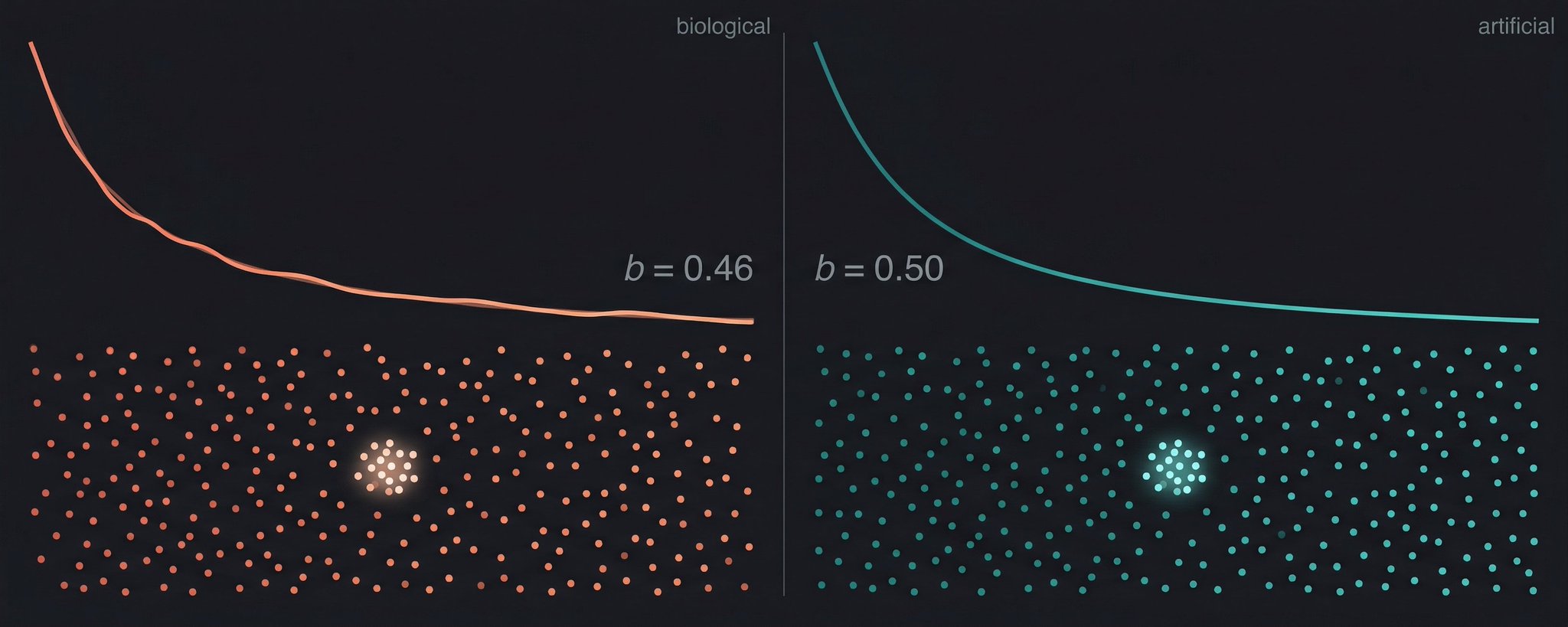
With decay alone and no competitors, the forgetting exponent was b ≈ 0.009. That is fifty times smaller than the human value of b ≈ 0.5. Decay by itself does not produce human-like forgetting. It produces almost no forgetting at all.
Adding 10,000 distractors while keeping the decay function unchanged raised the exponent to b = 0.460 ± 0.183, squarely within the range of human data. Time is not what produces forgetting in this system. Crowding is. The forgetting curves fan out progressively as competitors accumulate, converging toward the classical Ebbinghaus curve.
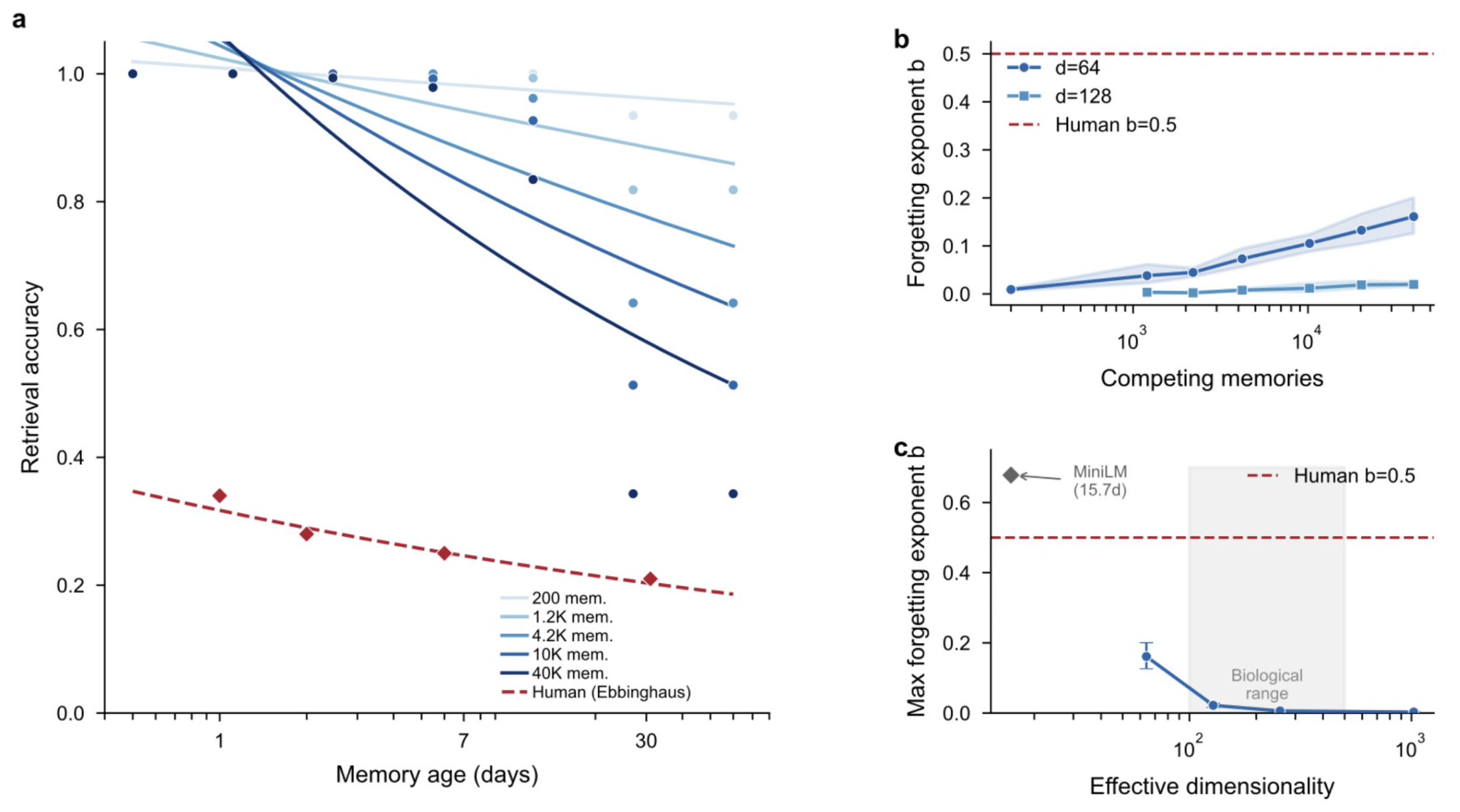
Interference, not decay, produces human-like forgetting. Left: forgetting curves steepen progressively as competing memories are added (light to dark blue), converging toward the classical Ebbinghaus curve (red dashed). All curves use the identical decay function; only competitor count changes. Center: the forgetting exponent increases monotonically with competitor count at d=64 (blue) but remains near zero at d=128 (grey), showing that dimensionality provides protection. Right: maximum forgetting exponent as a function of effective dimensionality. Interference is substantial only below d ≈ 100, placing biological neural codes (estimated d=100 to 500, shaded) near the transition zone. The orange diamond marks MiniLM (d_nom=384, d_eff ≈ 16), which shows strong interference consistent with its low effective dimensionality.
Think about what this means. The conventional story is that memories fade, like ink on paper exposed to sunlight. The geometric story is different. Memories do not fade. They get lost in a crowd. The ink is still there, but someone piled 10,000 other pages on top, and when you go looking for yours, you pull out the wrong one. The passage of time is correlated with forgetting only because more time means more competing memories have been stored in the interim. The dose-response relationship confirms it: more competitors, more forgetting, monotonically, with the exponent tracking competitor count almost linearly.
The dimensionality illusion
Here is where the SpectralQuant connection becomes direct.
An apparent paradox arises: if interference requires low dimensionality (d ≤ 64 in our experiments), how can it be relevant to production embedding models with 384 to 1,024 nominal dimensions?
The answer is what we call the dimensionality illusion, and it is the same spectral concentration we exploited in SpectralQuant. When we computed the participation ratio across three production embedding models, all of them concentrated their variance in roughly 16 dimensions, regardless of their advertised dimensionality. A model that claims to be 1,024-dimensional but concentrates its variance in 16 is not actually providing 1,024 dimensions of protection against interference. It is providing 16.
We confirmed the functional consequence directly. Running the interference protocol on MiniLM at its native 384 dimensions without any PCA projection produced catastrophic results: same-article distractors caused complete retrieval collapse at 20 or more distractors per target. The fitted forgetting exponent reached b = 0.678, far exceeding the b = 0.161 observed for BGE-large projected down to 64 dimensions via PCA. The effective dimensionality, not the nominal dimensionality, determines interference vulnerability.
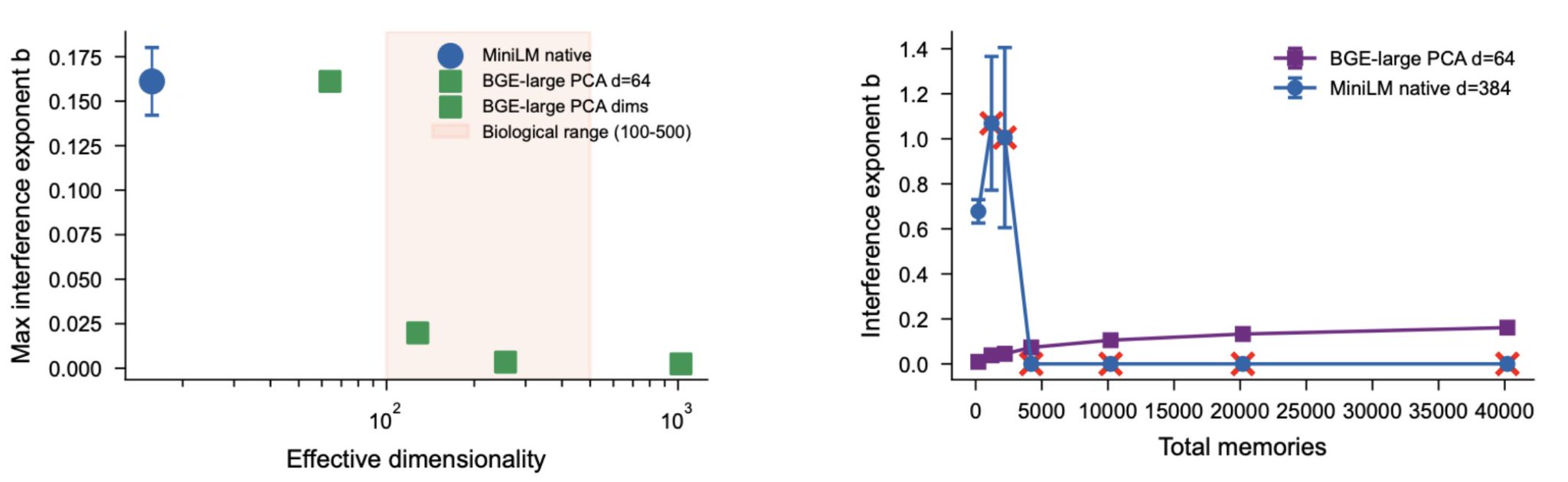
Effective dimensionality, not nominal dimensionality, determines interference. Left: MiniLM at native d=384 (d_eff ≈ 16, orange diamond) shows stronger interference than BGE-large projected to d=64, consistent with its low effective dimensionality. Biological cortex (estimated d=100 to 500, shaded) sits near the transition zone. Right: direct comparison confirms that MiniLM at 384 nominal dimensions collapses faster than BGE-large at 64 PCA dimensions, because MiniLM's effective dimensionality is only 16.
The practical implication for anyone building RAG systems or long-term agent memories: your vector database will eventually forget. This is not a worst-case scenario. It is the expected behavior, predictable from first principles. Retrieval accuracy will degrade as a power law with database size. Every vector database that grows without bound is running the same forgetting experiment that Ebbinghaus ran in 1885.
False memories require no engineering at all
This is the result that surprised us most.
The Deese-Roediger-McDermott (DRM) paradigm is the gold standard for studying false memory in humans. Participants study word lists built around a theme (bed, rest, awake, tired, dream...) and then are asked which words they saw. Roughly 55% of the time, they "remember" an unstudied word that is semantically related to the list (sleep). This is not a trick of phrasing or experimental design. People genuinely believe they saw the word. It is one of the most robust findings in cognitive psychology.
We replicated this paradigm using all 24 published DRM word lists encoded with a 1,024-dimensional retrieval model. We did not tune anything. We did not engineer a false memory system. We just computed cosine similarity between a query and each encoded word, applied a threshold, and asked: does the model "remember" the unstudied lure?
At the threshold that produces zero unrelated false alarms (an independent criterion, not tuned to match human data), the critical-lure false alarm rate was 0.583. The human value is approximately 0.55. Within 3.3 percentage points, with zero parameter adjustment.
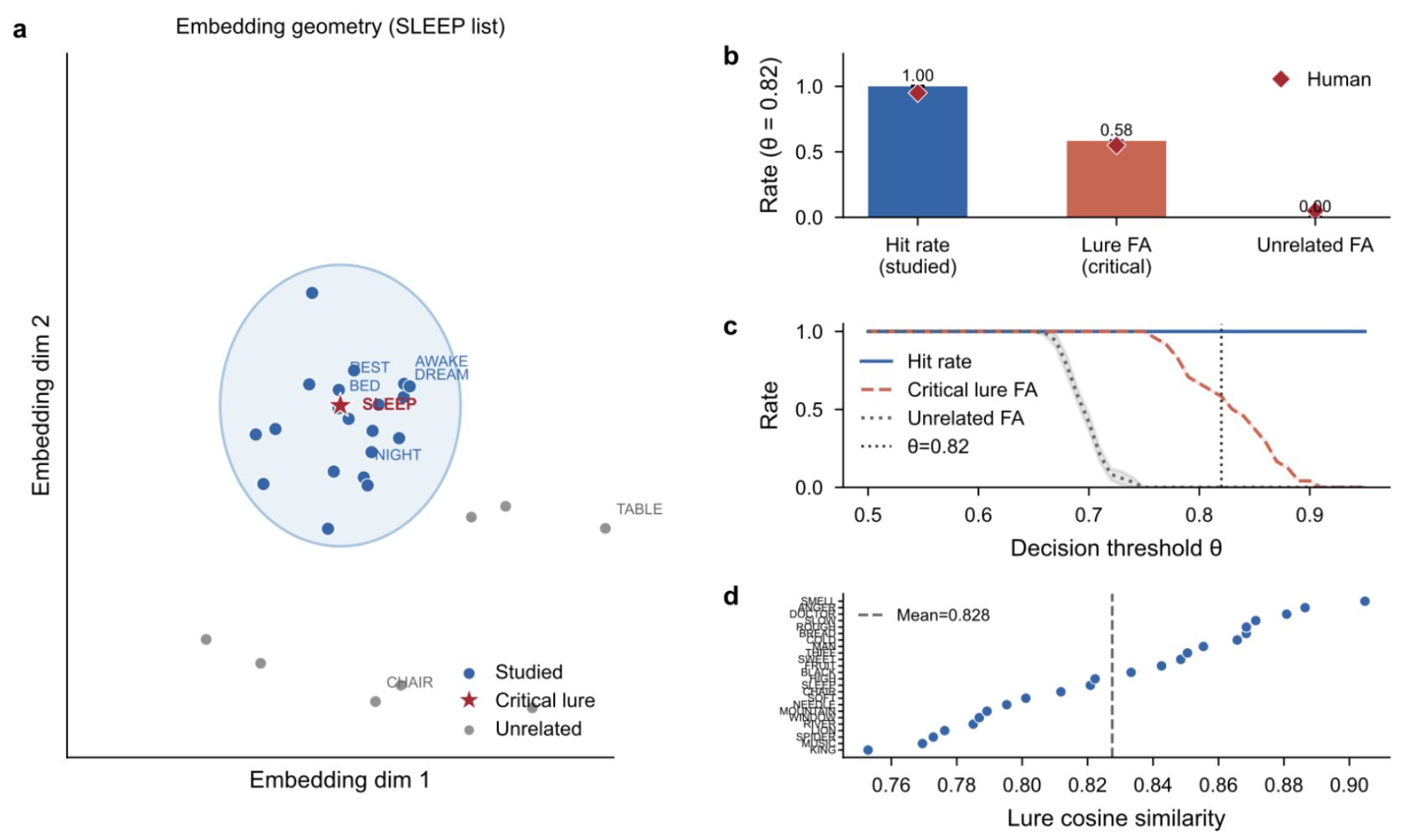
False memories emerge from the geometry of semantic space, with no engineering required. Top left: UMAP projection of the SLEEP word list shows the critical lure (sleep, red star) falling within the cluster of studied words (blue dots), geometrically indistinguishable from words that were actually presented. Unrelated words (grey) sit far away. Top right: at the threshold producing zero unrelated false alarms, the lure false alarm rate (0.583) matches the human value (~0.55, red diamonds) within 3.3 percentage points. Bottom left: threshold operating curves show the lure false alarm rate remains elevated above unrelated across a wide range of thresholds. Bottom right: the effect is consistent across all 24 published DRM word lists.
The reason this works is visible in the geometry. The embedding space puts semantically related concepts in the same neighborhood, and any threshold-based retrieval system will confuse items within that neighborhood. This result has an important asymmetry with the forgetting result. Forgetting requires competitors. You need to add distractor memories before the system starts forgetting. False memories require nothing. They sit in the geometry of meaning itself, waiting to be retrieved. We did not build a false memory system. We found one already present in the raw geometry of semantic space.
The implication is uncomfortable. False memories are not errors introduced by faulty hardware. They are a cost of the same geometry that supports generalization and pattern completion. A memory system that never confuses related concepts is a memory system that cannot generalize across them. This is a tradeoff frontier, not a design flaw.
The dimensionality protection curve
We varied the effective dimensionality to map out exactly where interference becomes dangerous. The results draw a clear boundary.
At d = 64, interference is strong: 40,000 same-article competitors produce a forgetting exponent of b = 0.161, with clear power-law forgetting visible in the data. At d = 128, the maximum exponent drops to b = 0.020: interference exists but is mild. At d ≥ 256, the exponent remains below 0.004 regardless of competitor count. Interference is effectively eliminated.
This protection comes from the concentration of measure: in higher dimensions, random points are exponentially unlikely to fall within any fixed angular neighborhood. Think of it this way. In 2 dimensions, a "similar" region around a point is a wedge that covers a meaningful fraction of the circle. In 128 dimensions, the equivalent wedge covers an exponentially tiny fraction of the hypersphere. The probability of a random competitor landing in your neighborhood drops toward zero as dimensionality increases.
And here is the connection to the brain. Cortical representations are estimated to operate at effective dimensionalities of 100 to 500. That places biological memory near the transition zone: enough dimensions to prevent catastrophic interference, but not enough to eliminate it. Human forgetting exponents (b ≈ 0.5) sit right in the regime our model predicts for moderate effective dimensionality with realistic competitor counts. We are not claiming this is proof that the brain uses the same mechanism. We are pointing out that the quantitative match is striking, and that it arises from geometry alone, without any biological modeling.
Spaced repetition works for geometric reasons
The spacing effect (distributed practice beats massed repetition) is one of the most robust findings in memory research. We replicated it: long-spaced retention = 0.994, medium = 0.382, short = 0.292, massed = 0.230, matching the human ordering (long > medium > short > massed) with a Cohen's d of 13.1.
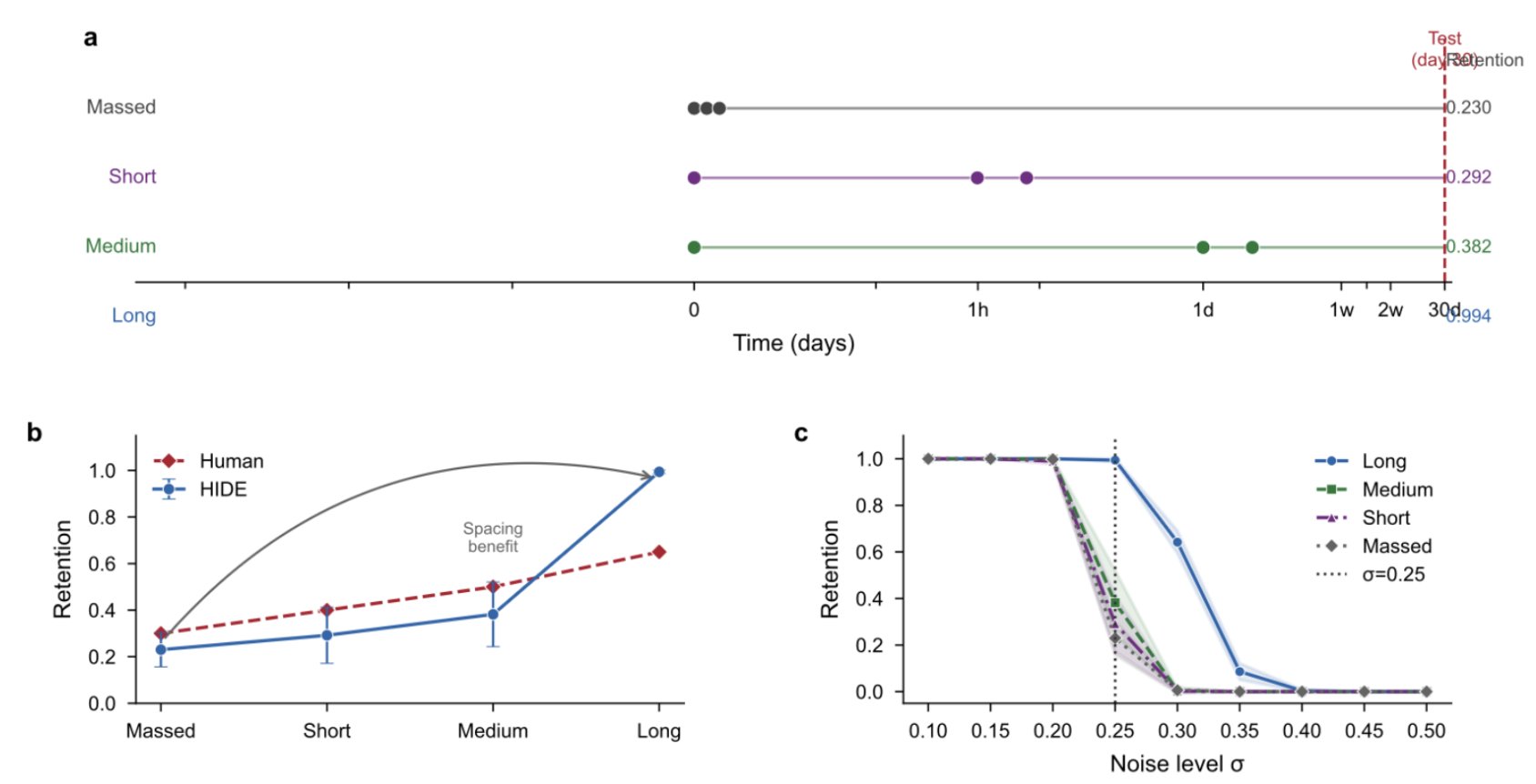
Spaced repetition survives age-dependent degradation. Left: timeline showing repetition schedules for each spacing condition. Long-spaced items retain a recent trace (14 days old) at test; massed items have only old traces (30 days). Center: retention increases monotonically with spacing interval, matching the human ordering (long > medium > short > massed). Right: the spacing gradient emerges as noise increases. At zero noise, all conditions achieve ceiling. As noise grows, conditions separate, with massed dropping fastest. The mechanism is geometric: a more recently encoded trace is less degraded by noise at test.
The mechanism is straightforward in the geometric framework. A more recently encoded trace is less degraded by noise at test. Long-spaced practice ensures that one repetition is always relatively recent; massed practice ensures all repetitions are equally old. The spacing gradient emerges as noise increases from ceiling performance, paralleling encoding variability theory from the psychology literature.
Tip-of-tongue states emerge from retrieval competition
We observed tip-of-tongue states (cases where the correct memory ranks 2 to 20 with high similarity, meaning the system "almost" retrieves it) at 3.66 ± 0.13% compared to the human rate of approximately 1.5%.
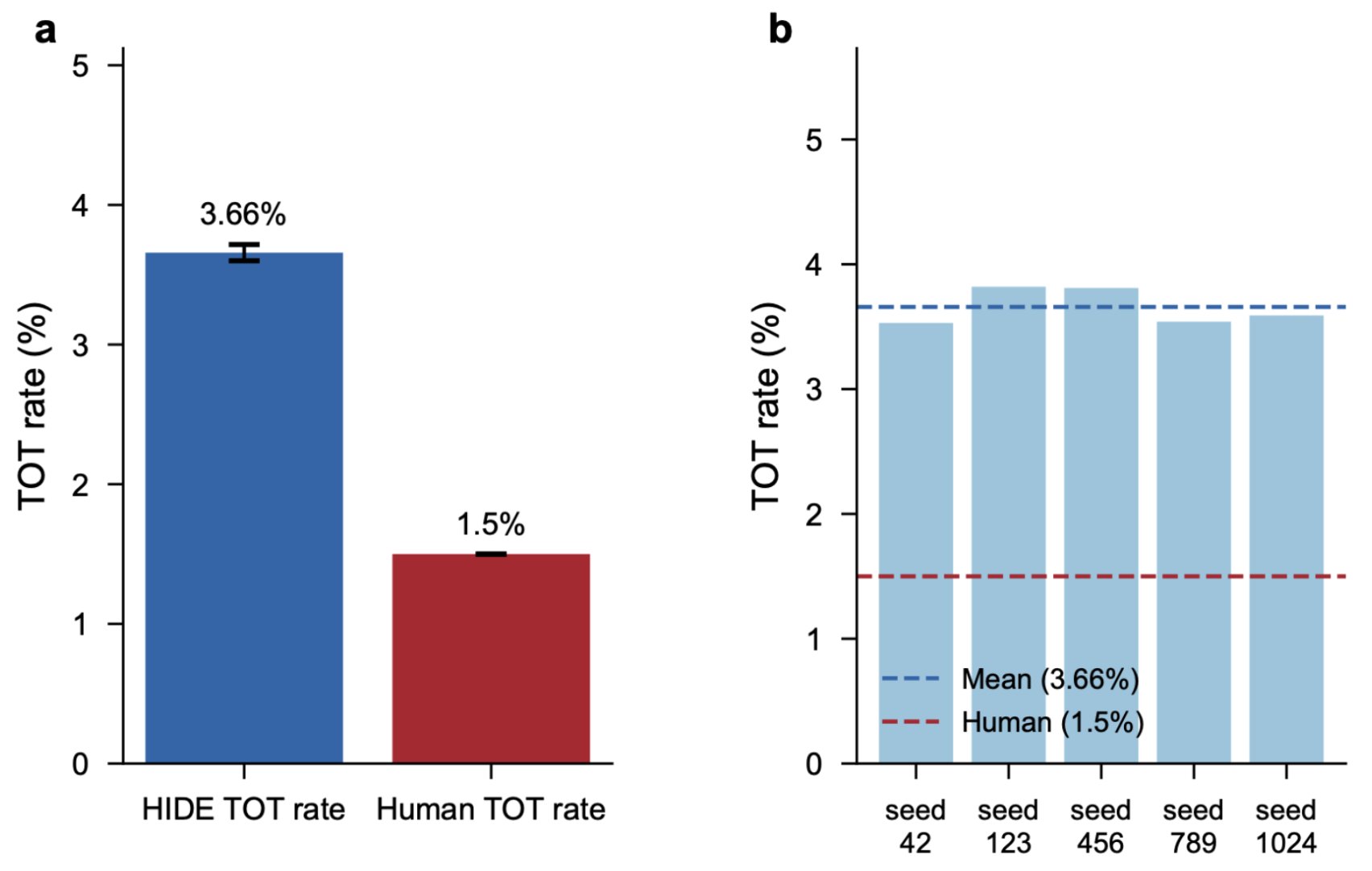
Tip-of-tongue states emerge from retrieval competition. The system 'almost' retrieves the correct answer (ranking it 2nd through 20th) at 3.66% compared to the human baseline of ~1.5%. The qualitative phenomenon (you know you know it, but you cannot quite get it) emerges naturally from competition in a crowded embedding space. The rate is higher than in humans by a factor of about 2.4, suggesting that biological systems have stabilizing mechanisms that narrow the parameter space beyond what geometry alone specifies.
The qualitative phenomenon (you know you know it, but you cannot quite get it) emerges naturally from retrieval competition in a crowded embedding space. The rate is higher than in humans by a factor of about 2.4, suggesting that biological systems have stabilizing mechanisms (attentional gating, consolidation) that narrow the parameter space beyond what geometry alone specifies. We present this as qualitative emergence, not quantitative correspondence.
The full scorecard: geometry vs human data
Across all five phenomena, the geometric framework produces a consistent pattern of matches and near-misses. The forgetting exponent and the DRM false alarm rate show the closest correspondence. Other phenomena show qualitative agreement with systematic (not random) discrepancies.
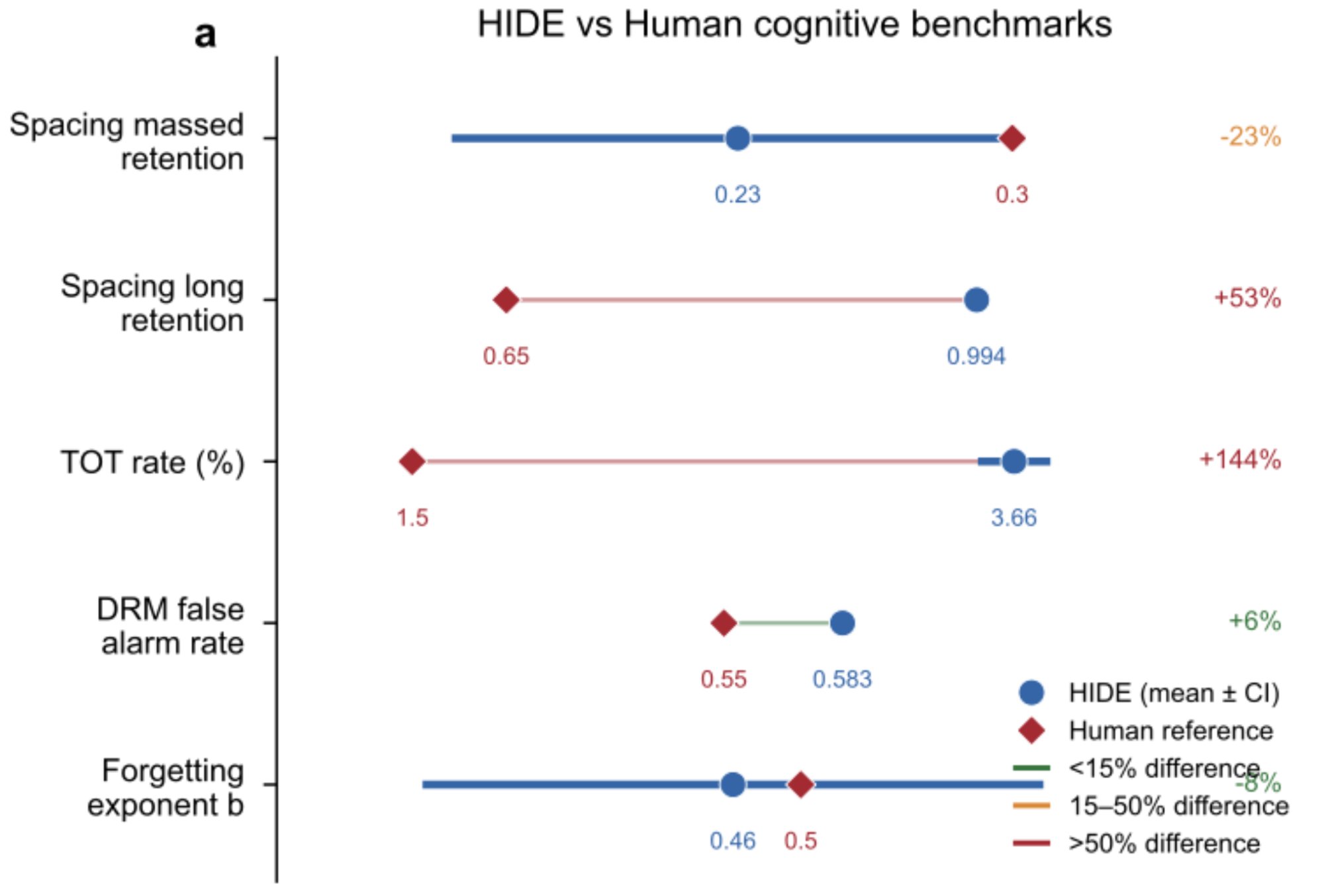
Geometric memory vs human cognition across five phenomena. For each, the observed value (blue dot, with 95% confidence interval) is compared to the corresponding human reference (red diamond). The forgetting exponent and DRM false alarm rate show the closest correspondence (within 8% and 6% respectively). The spacing effect and tip-of-tongue rate show qualitative but not tight quantitative agreement, with systematic discrepancies that point toward specific biological constraints that narrow the parameter space beyond what geometry alone specifies.
What this says about brains and LLMs
These results are not an analogy. Biological and artificial memory systems share failure modes because both are subject to the same geometric constraints: low effective dimensionality, semantic clustering, noise, and competition. The phenomena span a continuum from fully emergent to boundary-condition-dependent. False memories sit at the fully emergent end: they require no boundary conditions at all, just the raw geometry of semantic space. Forgetting sits in the middle: it requires competitor memories, but the decay function alone is insufficient. The spacing effect sits toward the contingent end: it requires specific noise and competitor parameters. That all three emerge from a single framework, at different points on this continuum, is itself evidence for a unified geometric account.
The convergence with the SpectralQuant findings is not a coincidence. The same spectral concentration (d_eff as a small fraction of nominal dimensionality) appears in KV cache attention heads, in production embedding models, and (based on neural recordings) in biological cortex. In each case, the participation ratio tells you something fundamental about the system. In the KV cache, it tells you how to compress. In embedding-based memory, it tells you how the system will forget. In both cases, the answer is governed by the eigenvalue spectrum: how many dimensions are doing real work, and how much protection the remaining dimensions provide against interference.
Biology determines where in parameter space a given system sits. Geometry determines what happens when it gets there. For the core phenomena examined here, the boundary between biological and artificial memory is thinner than previously assumed.
The vector averaging fallacy
One result from the paper has immediate engineering implications. We tested whether geometric consolidation (merging nearby embeddings by averaging them) could compress a growing memory store without losing retrieval quality. It cannot. Centroid merging achieved 62.5% compression but increased backward interference from -0.100 to -0.394: a nearly 4x degradation.
The reason is now obvious in light of the spectral structure. Averaging two nearby embeddings collapses the fine angular distinctions that separate them. In a low-effective-dimensionality space, those angular distinctions are already thin. Averaging destroys them entirely. This is the vector averaging fallacy: the widespread engineering practice of compressing retrieval databases or summarizing conversation histories by averaging nearby embeddings is not merely suboptimal but geometrically destructive.
If you are building a system that deduplicates embeddings by merging similar ones, or summarizes conversation history by averaging chunks, you are running the consolidation experiment we ran. The result will be the same. Retrieval fidelity will degrade, and it will degrade in exactly the way our experiment predicts: not randomly, but specifically by confusing items that were previously distinguishable.
The broader picture
Here is how the three works fit together.
SpectralQuant discovered that KV cache key vectors concentrate in ~4 out of 128 dimensions. We exploited that for compression: 18.6% better than the proven near-optimal bound, 4.5x faster attention, 15 seconds of calibration. The spectral gap was an opportunity.
The Shaped Cache experiment showed that variance concentration is not information: you cannot throw away the 97% of "noise" dimensions because they carry collectively decisive signal for the dot product. 420 experiments confirmed it. The spectral gap had limits.
The Geometry of Forgetting shows that the same spectral concentration governs what any similarity-based memory system can and cannot remember. Embedding models with d_eff ≈ 16 are operating in the interference-vulnerable regime, and the resulting forgetting curve matches the one Ebbinghaus measured in 1885. False memories emerge from the geometry of semantic space without any engineering. The spectral gap is not just a compression phenomenon. It is the geometry that determines how memory works, whether the substrate is silicon or cortex.
The same eigenvalue spectrum. Three different consequences. Compression, attention, memory. All governed by how many dimensions are doing real work.
Paper: The geometry of forgetting (Arxiv, 2604.06222)
Code and data: https://github.com/Dynamis-Labs/hide-project
This is the third in a series that began with 3% Is All You Need: Breaking TurboQuant's Compression Limit via Spectral Structure and continued with Variance is Not Information: The Shaped Cache Experiment. All three works grew out of the research program at Sentra, where we are building enterprise general intelligence: a shared AI layer that sits on all communication channels and agent traces to understand how everyone in an organization actually works and how work actually gets done, constructing a living world model of the entire company in near real time.