
TL;DR
Forgetting and false recall are mathematically, provably, inevitable for any memory system that organises information by meaning. Not just embeddings. Not just one architecture. Any system satisfying minimal conditions about semantic retrieval.
We tested five architecturally distinct systems (vector DBs, knowledge graphs, context windows, BM25/filesystem, parametric memory).
There is no escaping it. RAG, knowledge graphs, and parametric memory will always fail as long-term memory. These are choices you need to make, and this is a formal proof of that.
But there is a principled path towards a solution using filesystems that is explained here and a paper detailing everything.
There is a thread running through everything we have published over the last week, and it keeps pulling us deeper.
In SpectralQuant (blog, paper), we showed that KV cache key vectors concentrate in ~3% of their nominal dimensions and exploited that spectral gap to beat Google's provably near-optimal TurboQuant. It could be a lot more if combined with tri-attention, but that is a story for a different time. In The Geometry of Forgetting (blog, paper), we showed that the same spectral concentration governs memory: embedding spaces reproduce the quantitative signatures of human forgetting, false recall, and tip-of-tongue states with no phenomenon-specific engineering.
The question was whether that geometric vulnerability is an artifact of one architecture, or something deeper. Maybe a knowledge graph fixes it. Maybe a bigger context window. Maybe a filesystem.
This paper answers that question. The answer is no.
The theorem: why there is no escape
The core contribution of the paper "The Price of Meaning" is a formal no-escape theorem. It applies to any memory system that retrieves information by meaning. Not one particular architecture, but any system that works by placing memories in a semantic space and retrieving the closest matches. Here is the intuition.
Any memory system that retrieves by meaning has to represent concepts as points in some space, where "similar meaning" corresponds to "nearby points." That is what makes semantic retrieval work: related ideas land near each other. The problem is that language has a huge number of concepts but only a small number of truly independent dimensions of meaning. Empirically, across every model we tested, the effective dimensionality of semantic space is roughly 10 to 50, regardless of the nominal dimensionality of the embeddings. This is not a limitation of current models. It is a property of language itself.
When you pack a growing number of memories into a low-dimensional space, crowding is inevitable. New memories land near old ones not because they are related, but because there is nowhere else to go. This creates two problems that cannot be engineered away:
Forgetting. As more memories accumulate, older ones get crowded out by newer neighbours. Retrieval scores for the original memory decay, not because the memory was deleted, but because it was drowned out. The decay follows a power law, matching the shape of human forgetting curves.
False recall. Memories that are conceptually related but factually distinct ("the meeting about pricing" vs. "the meeting about packaging") land in overlapping regions. No threshold setting can accept all true matches and reject all false ones when the representations themselves are too close to separate.
The logical chain is tight: if your system retrieves by semantic similarity, and your representations are learned under any kind of efficiency constraint, and your semantic space has finite intrinsic dimension (which it always does for natural language), then forgetting and false recall are mathematically guaranteed as the memory grows. These are not bugs. They are the cost of organising information by meaning.
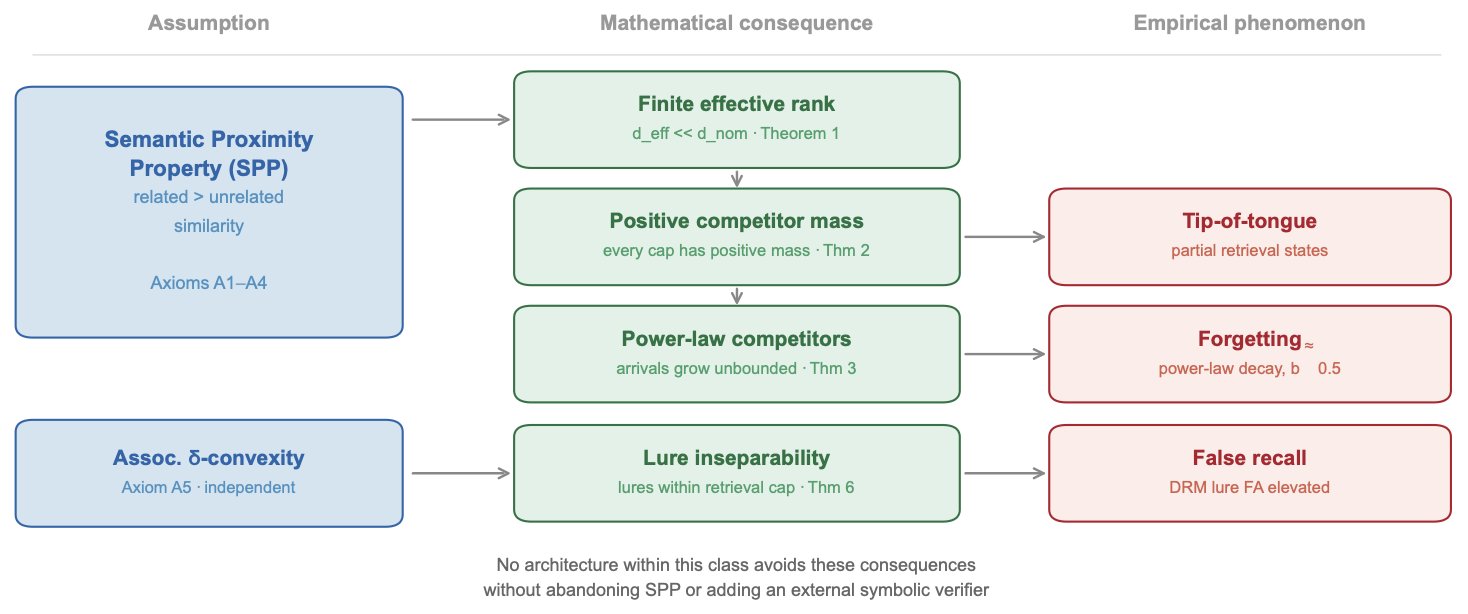
The No-Escape Theorem dependency chain. Shows the logical flow from the three core assumptions (semantic retrieval, efficient encoding, finite dimensionality) through to inevitable forgetting and false recall, with the five architectures mapped to three behavioural categories.
The no-escape theorem makes the tradeoff explicit: any architecture that simultaneously eliminates interference-driven forgetting and associative false recall must either abandon semantic retrieval entirely, add an external verification layer that provides exact episodic grounding, or somehow make the effective dimensionality of semantic space infinite. The first option kills usefulness. The third is physically impossible for natural language. That leaves the second, and it is exactly the direction we think is right.
Five architectures, three categories, one geometry
We did not just prove a theorem and stop. We tested it across five architecturally distinct memory systems:
1. Vector database (BGE-large, 1,024 dimensions, cosine similarity)
2. Attention-based context window (Qwen2.5-7B, 3,584-dimensional hidden states)
3. Filesystem agent memory (BM25 keyword search + LLM re-ranking)
4. Graph memory (MiniLM + PageRank)
5. Parametric memory (knowledge in LLM weights, probed via direct Q&A)
The results split into three categories that tell you everything about the tradeoff.
Category 1: Pure geometric systems (vector DB, graph memory)
The geometry IS the behaviour. These systems exhibit smooth power-law forgetting (b = 0.440, 0.478), robust DRM false recall (FA = 0.583, 0.208), the spacing effect, and tip-of-tongue states. No escape at either the geometric or behavioural level.
The graph memory result is important. Knowledge graphs are widely promoted as the solution to RAG's limitations: better multi-hop reasoning, explicit relationships, structured traversal. They do help with some retrieval patterns. But they do not escape the no-escape theorem. The graph memory (MiniLM + PageRank) produced b = 0.478 at 10,000 competitors. Squarely in the human range. Despite an entirely different retrieval mechanism. The geometry does not care about your architecture. It cares about your representations.
Category 2: Reasoning overlays (attention memory, parametric memory)
The geometric vulnerability exists (d_eff = 17.9 for Qwen hidden states, lures within caps), but the system can reason its way around it behaviourally. The LLM correctly rejects DRM lures by parsing word lists (FA = 0.000). But interference manifests differently: the attention architecture shows a phase transition where perfect accuracy holds with fewer than 100 competitors, then collapses to near-zero at 200+. Parametric memory shows monotonically decreasing accuracy with neighbour density (1.000 → 0.113).
The workaround converts graceful degradation into catastrophic failure. This is worse, not better. A system that degrades smoothly gives you warning. A system that holds perfectly then falls off a cliff does not.
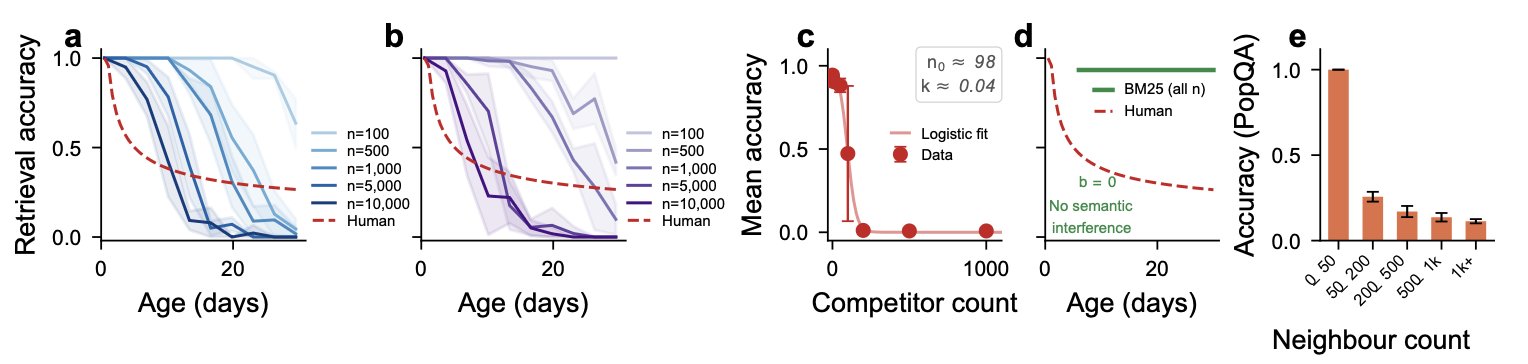
Interference produces forgetting across architecturally distinct memory systems. (a) Vector DB and (b) Graph show smooth power-law forgetting curves converging toward the human range (b ≈ 0.3–0.7, red dashed). (c) Attention shows a phase transition (logistic fit: n_0 ≈ 120, k ≈ 0.03; power-law fitting is inappropriate for this sigmoid failure mode). (d) Filesystem (BM25) shows b = 0 (no semantic interference). (e) Parametric (PopQA) shows monotonic accuracy decline with neighbour density. Category 1 systems degrade continuously; Category 2 systems fail discontinuously. n = 5 seeds throughout.
Category 3: Systems that abandon meaning (filesystem/BM25)
BM25 produces b = 0.000. FA = 0.000. No spacing effect. Complete immunity. But SPP correlation is r = 0.210 and semantic retrieval agreement is 15.5%. It escaped interference by escaping usefulness.
This IS the no-escape theorem in action. This is the proof, not the counterexample.
The filesystem moment, and what it actually tells us
There is a serious movement right now toward filesystems as the core abstraction for AI agent memory. Not the naive version, not "dump everything in a folder." The systems getting traction couple structured files with LLM reasoning, and they work surprisingly well.
ByteRover (April 2026) stores all knowledge as human-readable markdown in a hierarchical Context Tree with no vector database, no graph database, no embedding service, and achieves 92.8% accuracy on LoCoMo by having the LLM itself curate, structure, and retrieve knowledge as first-class tools in its reasoning loop.
Letta's filesystem benchmark showed that simply attaching conversation history as a file and giving the agent grep and semantic search tools scored 74.0% on LoCoMo with GPT-4o-mini, higher than Mem0's specialised graph memory variant.
Claude Code, Manus, and OpenClaw have all converged on markdown-based memory with LLM-driven retrieval.
The xMemory framework decouples memories into semantic components, organises them into a hierarchy, and retrieves top-down, beating RAG baselines while using 28 to 48% fewer tokens.
These are not toy systems. They are real architectures shipping in production, and the results are impressive. The filesystem discourse is correctly sensing that something is broken with pure semantic retrieval, and LLM-coupled filesystems are a genuine step forward.
But every one of these systems that achieves meaningful accuracy does so by reintroducing semantic understanding. ByteRover's Context Tree uses a full-text search index plus LLM reasoning to navigate its hierarchy. Letta's filesystem automatically embeds files for semantic vector search. xMemory clusters memories into semantic themes. The moment you add meaning-based retrieval (and you must, because pure keyword matching agrees with semantic retrieval on only 15.5% of queries) you are back inside the theorem.
The LLM-coupled filesystem is not an escape from the no-escape theorem. It is a sophisticated navigation of the tradeoff frontier the theorem describes. The filesystem provides exact episodic storage: the markdown files are precise records. The LLM provides semantic reasoning on top. That combination is genuinely better than a raw vector database, but the semantic component still inherits the geometric vulnerability. As the knowledge base grows, the LLM's semantic retrieval over those files will still crowd, still interfere, still produce false associations. The filesystem stores perfectly. The understanding layer does not.
What the filesystem movement has discovered, whether it knows it or not, is Option 2 of the no-escape theorem: augment semantic retrieval with an exact episodic record. The files are the episodic record. The LLM is the semantic layer. The instinct is exactly right. The question is whether the coupling between the two is principled enough to manage the tradeoff as memory scales to organisational size: thousands of agents, millions of facts, years of history.
A principled reason to retire RAG and knowledge graphs
Let me be direct about what this paper means for the current generation of memory architectures.
RAG will always fail. Not "might fail at scale." Not "fails in edge cases." The no-escape theorem proves that any retrieval-augmented generation system built on dense embeddings will exhibit interference-driven forgetting and false recall as the knowledge base grows. The forgetting exponent, the false alarm rate, and the tip-of-tongue probability are continuous functions of system parameters, but the theorem says these functions are bounded away from zero. You can tune. You cannot eliminate.
Knowledge graphs will always fail. Despite the pitch that graph structure solves RAG's problems, our graph memory (MiniLM + PageRank) produced forgetting and false recall squarely in the human range. The graph traversal helps with multi-hop reasoning, yes. But the underlying representations are still semantic embeddings, the retrieval still operates on inner products, and the geometry still produces interference. A knowledge graph built on dense embeddings is a semantic memory system with extra steps. It inherits the same geometric vulnerability.
Parametric memory will always fail. The most striking result in the paper: Qwen2.5-7B's accuracy on factual questions drops from 1.000 to 0.113 as the density of semantically similar facts in the training corpus increases. This is interference in model weights, not in an external store, not in a context window, but in the parameters themselves. Making the model bigger moves you along the tradeoff surface. It does not remove the tradeoff.
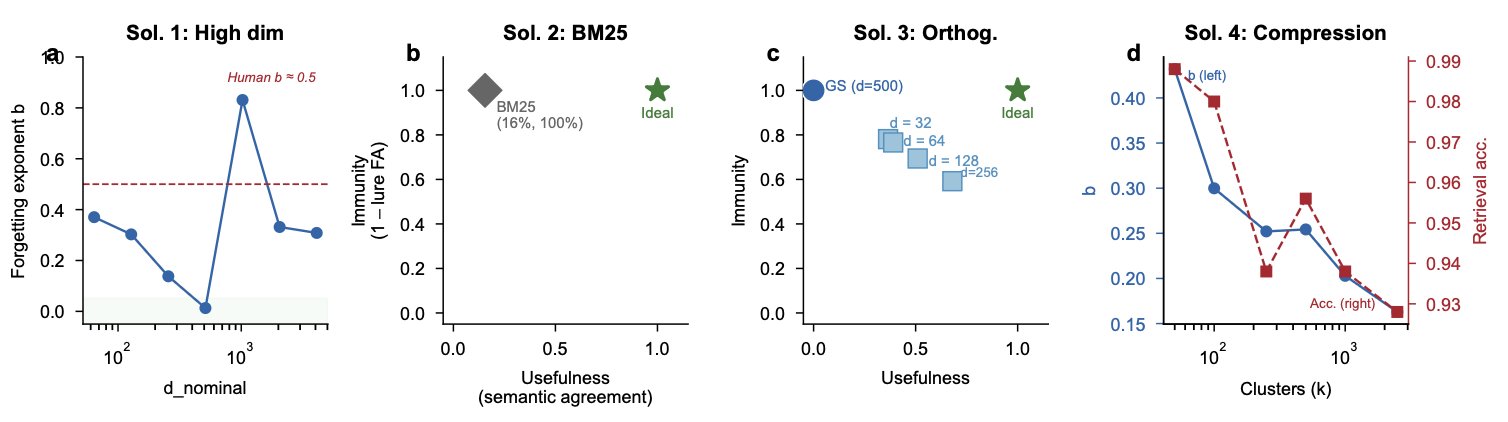
No proposed solution achieves both immunity and usefulness. Every solution that reduces interference moves along a tradeoff frontier toward reduced usefulness; no solution escapes the frontier itself. (a) Zero-padding does not reduce b because d_eff is unchanged. (b) BM25 eliminates false recall but semantic agreement drops to 15.5%. (c) Gram-Schmidt eliminates interference; semantic accuracy drops to 0%. (d) Compression reduces b but degrades retrieval. This is the no-escape theorem in empirical form.
Every solution we tested traces a strict Pareto frontier between interference immunity and semantic usefulness:
Increase nominal dimensionality. Zero-padding from 1,024 to 4,096 dimensions: b stays at ~0.31 because d_eff is unchanged.
BM25 keyword retrieval. Eliminates forgetting and false recall. Semantic agreement: 15.5%.
Orthogonalisation. Reduces interference to zero. Nearest-neighbour accuracy drops to 0.0%.
Memory compression. At 2,500 clusters: b = 0.163, accuracy = 0.928. The tradeoff is monotonic.
The theorem does not claim that interference cannot be reduced. It claims it cannot be eliminated without sacrificing semantic usefulness. The tradeoff frontier itself is the no-escape theorem in empirical form.
The dimensionality convergence
The label "3,584-dimensional" is, in a functionally meaningful sense, a misnomer.
Despite nominal dimensionalities spanning an order of magnitude (384 for MiniLM to 3,584 for Qwen2.5 hidden states), effective dimensionality converges dramatically. BGE-large: d_eff = 158 (participation ratio), d_eff = 10.6 (Levina-Bickel). MiniLM: d_eff = 127. Qwen2.5-7B hidden states: d_eff = 17.9, a 200-fold compression.
The Levina-Bickel estimator, which measures local manifold dimensionality, gives d_eff ≈ 10 to 15 across all models. This is the governing quantity for interference, because interference occurs in local neighbourhoods (the θ-cap of the positive cap mass theorem), and the crowding within these neighbourhoods is determined by the local manifold dimensionality, not by the global variance spread.
The convergence is not coincidental. Any encoding that satisfies the Semantic Proximity Property must concentrate variance in the ~10 to 50 semantically meaningful directions. Biological neural populations operate at estimated d_eff = 100 to 500, placing them near the transition zone. The same zone we found in The Geometry of Forgetting. The same zone that SpectralQuant exploited for compression.
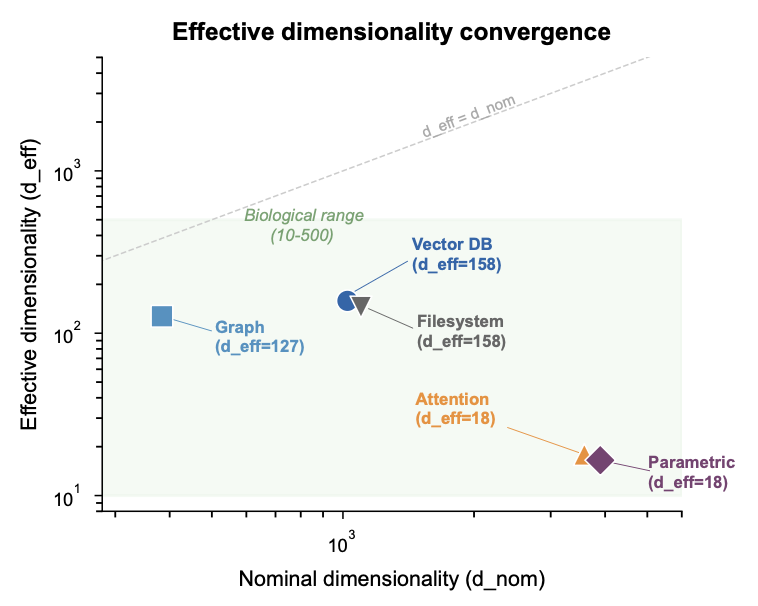
Effective dimensionality converges far below nominal regardless of architecture. d_eff (participation ratio) vs. d_nom for all five architectures. Grey: biological range (d_eff = 100–500). Qwen hidden states (d_nom = 3,584) compress to d_eff = 17.9, a 200x reduction. All architectures cluster below the interference threshold.
Same eigenvalue spectrum. Same spectral concentration. Different consequences depending on what you are trying to do.
What the theorem does not say
The theorem bounds the existence of interference, not its magnitude. The gap between "inevitable" and "catastrophic" is where engineering contributes. The forgetting exponent, the false alarm rate, the TOT probability are all continuous functions of system parameters. You can and should optimise noise parameters, manage competitor density through intelligent caching, and design consolidation strategies that navigate the compression-fidelity frontier.
Memory compression at k = 2,500 achieves b = 0.163 with 92.8% accuracy. That is a potentially acceptable engineering compromise for specific applications. But it is not mathematical immunity. It is a point on the tradeoff frontier.
The standard engineering response to forgetting and false recall is to treat them as bugs and try to fix them. Our results suggest they are not bugs. They are the cost of admission. Any memory system that organizes information by meaning will, as it grows, forget old items through interference and falsely recognise items it never stored. These are not signs of a broken system. They are signs of a system doing what it was designed to do, representing meaning geometrically, under the constraints that geometry imposes.
But there is a way forward
The no-escape theorem identifies three exits from the theorem class:
Abandon semantic continuity (the filesystem solution: works, but kills usefulness)
Add an external symbolic verifier or exact episodic record
Send the semantic effective rank to infinity (impossible for natural language)
Option 2 is the principled path. The theorem tells you exactly what a correct memory architecture needs: a semantic layer for generalisation and retrieval by concept, coupled with an external verification layer that provides exact episodic grounding. Neither alone is sufficient. Together, they can navigate the tradeoff frontier rather than being trapped on it.
The complementary learning systems hypothesis from neuroscience can be reinterpreted through this lens: fast hippocampal encoding and slow neocortical consolidation manage the interference-usefulness tradeoff. They do not eliminate interference. They manage the position on the tradeoff frontier. Even the brain's most sophisticated consolidation mechanism does not escape interference. It navigates it.
A principled memory architecture would do the same: use semantic representations for what they are good at (generalisation, analogy, conceptual transfer), use exact episodic records for what they are good at (precise recall, contradiction detection, source verification), and manage the boundary between them with interference-aware consolidation.
This is what we are building at [Sentra](https://sentra.app/). Not a bigger vector database. Not a more elaborate knowledge graph. A memory architecture that takes the no-escape theorem seriously, that understands the price of meaning and pays it deliberately rather than pretending it does not exist.
The broader picture
Here is how the works fit together.
SpectralQuant (paper) discovered that KV cache key vectors concentrate in ~4 out of 128 dimensions. We exploited that for compression: 18.6% better than the proven near-optimal bound. The spectral gap was an opportunity.
The Geometry of Forgetting (paper) showed that the same spectral concentration governs memory. Embedding models with d_eff ≈ 16 are operating in the interference-vulnerable regime, and the resulting forgetting curve matches Ebbinghaus 1885. False memories emerge from the geometry of semantic space without any engineering. The spectral gap is a vulnerability.
The Price of Meaning (this article, paper) proves the vulnerability is inescapable. It is not an artifact of one architecture. It is a structural consequence of semantic organisation under finite effective dimensionality. Across five architectures, the geometry holds. The behavioural expression varies (smooth degradation, phase transitions, or complete immunity at the cost of usefulness) but the underlying geometric vulnerability is universal within the theorem class.
Same eigenvalue spectrum. Three different consequences. Compression, attention, memory, and now: the mathematical limits of memory itself. The price of meaning is interference. Within this theorem class, there is no escape. But there is a principled solution that takes all of it into account.
---
Paper: The Price of Meaning: Why Every Semantic Memory System Forgets (https://arxiv.org/html/2603.27116v1)
Code and data: https://github.com/Dynamis-Labs/no-escape
---
This is the fourth in a series that began with SpectralQuant, the about shaped KV cache and The Geometry of Forgetting: Why Brains and LLMs Fail EXACTLY the Same Way. All four works grew out of the research program at Sentra, where we are building enterprise general intelligence: a shared AI layer that sits on all communication channels and agent traces to understand how everyone in an organization actually works and how work actually gets done, constructing a living world model of the entire company in near real time.