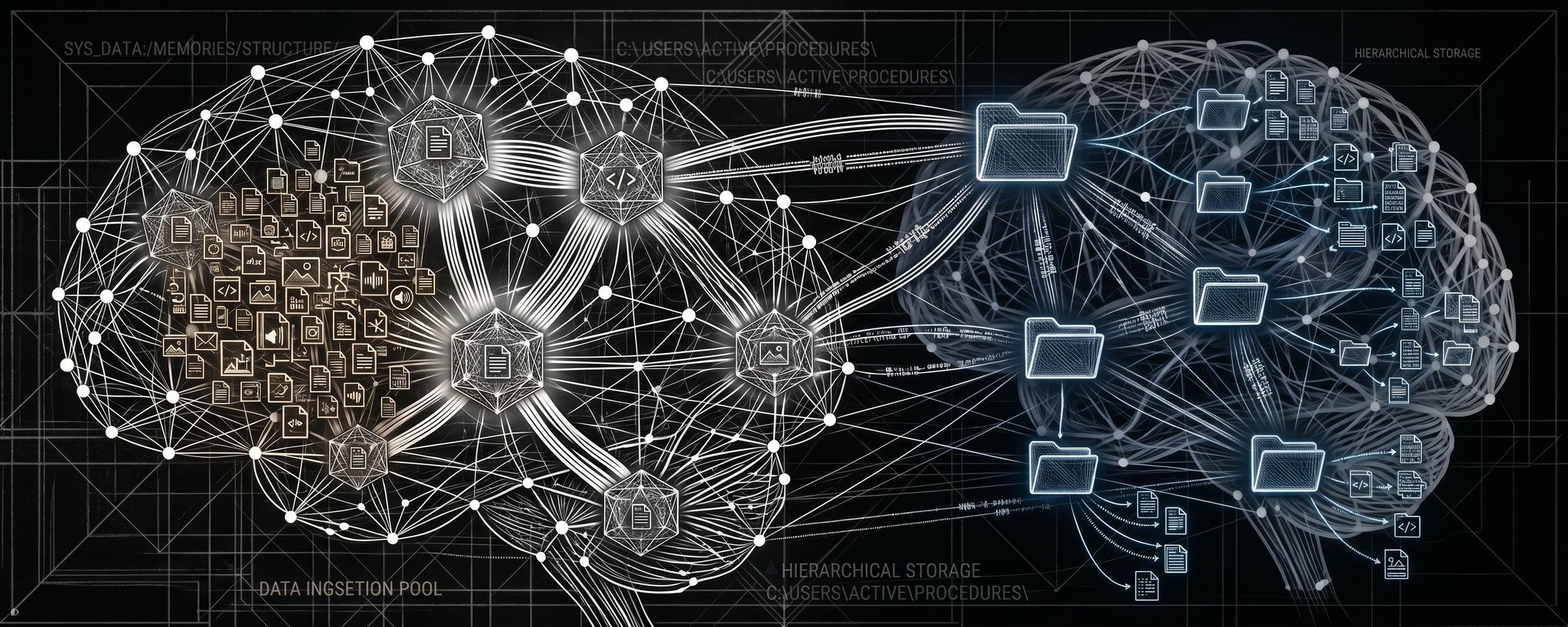
TL;DR
A designer sees the Golden Gate Bridge and remembers International Orange. An engineer sees cables. A biologist remembers a whale. Same object, three memories, because memory is not knowledge storage. It is a utility function.
Karpathy's LLM Wiki and Garry Tan's GBrain are building knowledge bases, structured records of what is true. Memory is something else: it encodes why something matters, to whom, and manages how that changes over time. The difference matters at scale.
Obsidian wikilinks create a graph, but one you cannot query programmatically, traverse multi-hop, or put access controls on. Flat markdown does not scale.
SMF is our response: POSIX symlinks are the knowledge graph edges. ls -la reveals the graph. No separate graph database. Native access control. Scales to millions of entities without touching a context window. With Amazon S3 Files (April 2026) delivering native POSIX filesystem semantics on S3, the entire SMF architecture can now run on cloud-scale object storage with S3 durabilityand pricing.
Structure over scale: on LoCoMo, a well-structured filesystem-native memory with BM25 + graph traversal achieves the same strict J-score as a much richer 14+ channel stack, and a 50× model scale increase only buys +0.081 J-score under a dedicated GPT‑4.1 judge. Architecture dominates scale.
We are open-sourcing the core. Production goes further. https://github.com/dynamis-Labs/SMF
Memory is another meta problem with AI, and it is one that the field is approaching from the wrong direction.
The instinct is to build bigger knowledge bases. Index more documents. Store more facts. Embed everything. The assumption is that memory is a retrieval problem, that if you can find the right document when you need it, you have solved memory.
This is wrong, and we showed why in The Price of Meaning: any memory system that retrieves by semantic similarity will exhibit interference-driven forgetting and false recall as it grows. No architecture within the theorem class avoids this (the proof is in the paper). The theorem identified three exits: abandon semantics (kills usefulness), send effective dimensionality to infinity (impossible), or add an external symbolic verifier that provides exact episodic grounding. The same spectral concentration we exploited for compression in SpectralQuant and mapped to memory failure in The Geometry of Forgetting is what makes the problem inescapable.
External symbolic grounding was the only viable exit. And here is the empirical punchline: once you build the right retrieval structure around that grounding, a carefully structured filesystem-native memory backed by an 8B or 70B model can sit within a few points of a frontier model under strict judging, and a dramatically simplified retrieval stack (BM25 + graph + facts + temporal) matches a full 14+ channel stack on J-score.
Architecture dominates scale. SMF is that architecture.
Code is at https://github.com/dynamis-Labs/SMF
Knowledge bases are not memory
Before we describe the architecture, we need to be precise about a distinction that the current conversation conflates.
In early April 2026, Andrej Karpathy shared his approach to building personal knowledge bases with LLMs. The system is elegant: drop raw sources into a raw/ folder, have an LLM compile them into a wiki of ~100 interlinked markdown articles (~400K words), use Obsidian as the IDE, and let the LLM auto-maintain index files and backlinks. No vector database. No embedding pipeline. Karpathy noted: “there is room here for an incredible product.” He was right, the approach works remarkably well at personal scale.
Days later, Garry Tan, CEO of Y Combinator, open-sourced GBrain: a TypeScript/Bun system backed by PostgreSQL + pgvector that indexes 10,000+ files, builds entity relationships and cross-references, and runs a nightly “dream cycle” that enriches the knowledge graph while you sleep. GBrain has entity types, cross-referencing, 30+ MCP tools, and a “compiled truth + timeline” pattern that separates current synthesis from append-only evidence.
Meanwhile, the Obsidian community has been building graph-structured knowledge systems using wikilinks ([[ ]]) to create bidirectional connections between notes. The graph view is beautiful. Tools like Cognee bolt on LLM-driven entity extraction and relationship mining. Developers are using Obsidian vaults as persistent memory for Claude Code, Cursor, and other AI agents.
These are all genuine contributions. We want to honor what they represent: a clear-eyed recognition that files beat vector databases, that human-readable formats outlast proprietary APIs, and that structure matters. Every engineer who has tried to debug a 1,024-dimensional embedding query understands viscerally why this movement exists.
But there is a distinction worth being precise about.
Karpathy's LLM Wiki is a knowledge base, and he positioned it as exactly that. The LLM compiles, organises, and interlinks facts. The output is a structured personal reference. The distinction we are drawing is not a critique of what he built, it is a clarification of where the broader conversation conflates knowledge bases with memory. The wiki solves knowledge management at personal scale. It does not model who needs what information and why. It does not weigh relevance against purpose. It does not forget. Memory requires something more.
GBrain is a richer knowledge base. The entity relationships and cross references bring it closer. The dream cycle adds temporal enrichment. But the architecture is fundamentally “compiled truth”, a running synthesis of what Garry Tan knows, stored in PostgreSQL with vector search bolted on. It depends on an external database service to function. It does not encode access control at the storage level. It does not model the purpose of remembering. It is a knowledge management system, and a good one. It is not memory.
Obsidian-based systems are graph-shaped knowledge bases. Wikilinks create connections, and the graph view visualises them. But you cannot query that graph programmatically. There is no multi-hop traversal. There are no typed relationships. There is no access control. And when the vault grows beyond what fits in a context window, the system degrades, which is exactly why OpenClaw bolted on SQLite and vector search: “A folder of linked markdown files is not a graph database.”

Structural comparison table: Karpathy Wiki vs GBrain vs Obsidian vs SMF (this work)
The distinction matters because memory is not about recording what is true. Memory is about encoding what matters, to whom, for what purpose, and managing how that encoding changes over time. A knowledge base answers: “What do I know?” Memory answers: “What will I need?”
This has a direct consequence for how we interpret benchmarks. Knowledge base systems are optimised for information retrieval: given a query, find the most relevant document. Their benchmarks measure retrieval accuracy, and that is appropriate. But memory systems have a broader mandate. Retrieval is necessary but not sufficient. A memory system must also maintain relationships, manage lifecycle, enforce access control, handle contradictions, and forget what no longer matters. None of these capabilities are captured by retrieval benchmarks. When we compare SMF's LoCoMo numbers against ByteRover's or Letta's, we are comparing retrieval accuracy, one dimension of a multi-dimensional problem. The dimensions where SMF's architecture pays its highest dividends (relational durability, access control, scalability, lifecycle management) are not measured by any current benchmark.
This is where SMF enters.
Why memory is hard: the utility function problem
The retrieval gap is one dimension of the problem. But there is a deeper one that affects not just how we evaluate memory systems, but how we build them.
Memory depends on the observer's utility function.
Consider the Golden Gate Bridge. A designer looks at it and remembers International Orange, the colour Irving Morrow chose to complement the natural surroundings and maintain visibility in San Francisco's fog. A structural engineer looks at the same bridge and sees the cables: 80,000 miles of wire, 746-foot towers, the tensile forces that keep 894,500 tonnes of steel suspended across the strait. A marine biologist who was on a research vessel last Tuesday remembers a whale passing under it.
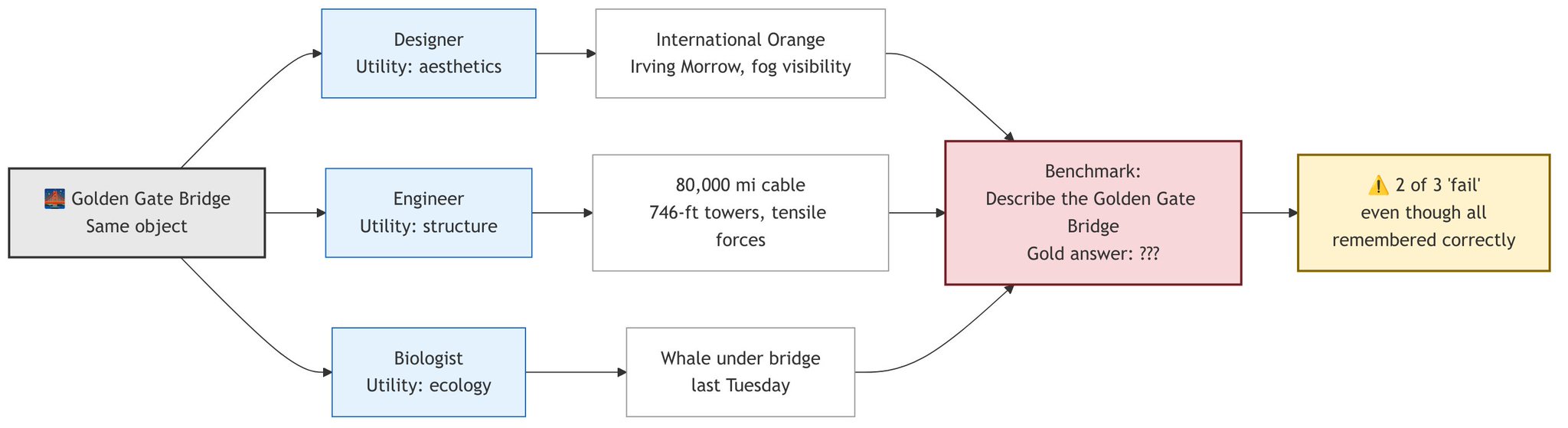
The utility function problem: same object, three observers, three memories
Same object. Three completely different memories. Not because anyone's memory is wrong, but because each observer has a different utility function, a different answer to the question: “What will I need to remember later?”
This creates a fundamental problem for benchmarking. If you ask all three observers about the Golden Gate Bridge and score their answers against a single gold reference, two of the three will appear to have “failed”, even though each remembered exactly what they needed to. Every memory benchmark implicitly bakes in a utility function: it decides which answers count as correct. When we score memory systems on LoCoMo or any other benchmark, we are not measuring memory quality in the abstract. We are measuring how well a system's utility function aligns with the benchmark's. This is not a grain of salt. It is the entire framing.
Memory is not about recording everything. It is purpose-driven compression. An organism (or an organisation, or an AI agent) that tries to remember everything about everything will drown in its own records. A system that knows what questions it will need to answer can be ruthlessly selective about what it stores and how it indexes it.
This has a direct and underappreciated consequence for memory systems. The narrower the memory's purpose, the easier it is to build the memory. An organisation's memory is easier than an individual's, because the utility function is more constrained: who is responsible, what was decided, what commitments were made, what the rationale was. An individual's memory is harder because the utility function is broader and less predictable. A general purpose AI agent's memory is hardest of all, because the utility function is essentially “anything the user might ask about anything that has ever happened.”
Karpathy's Wiki, GBrain, and Obsidian-based systems push the utility function into the LLM at query time: the model decides what matters when you ask. SMF encodes the utility function into the storage structure itself. The 8 entity types, the symlink schemas, the confidence scoring, the zone management, all of these are structural implementations of the claim that certain kinds of information matter more than others, and that relationships between those things matter most of all.
The strongest counterargument is that dynamic utility functions are more flexible. If the LLM decides at query time what matters, it can adapt to novel questions. This is true, and for personal tools it is the right tradeoff: your needs change constantly, re-reading is cheap, and a single user does not need access control. But for organisational memory, durability matters more than flexibility. Compliance, auditing, accountability, and multi-agent access all require that relationships survive model changes, employee turnover, and time. An organisation needs to know who decided what, when, why, and what was committed, and it needs those answers to be model-independent and permission-governed. That is where structural encoding wins.
We built SMF for organisational memory first because that is where the utility function is most constrained and therefore most encodable. But the architecture is not limited to this. The entity type system is a pluggable schema. A clinical memory might replace VCOs with diagnoses and rationale with treatment plans. A legal memory might track obligations, precedents, and jurisdictions. A research memory might track hypotheses, experiments, and evidence chains. The structural principle, encode your utility function
into typed entities connected by symlinks, is general. The specific entity types are the part you adapt to your domain.
What SMF does differently: the filesystem IS the knowledge graph
The central architectural insight of SMF is that POSIX symlinks, the humble ln -s that every Unix system has supported for nearly half a century, are zero cost relational pointers. A symlink from /memory/actors/alice/related/collaborated_with/bob to /memory/actors/bob/ is a typed, directed edge in a knowledge graph. It costs almost nothing to create. It costs almost nothing to traverse. It requires no separate graph database. And ls -la reveals the relationship structure to any human or agent that looks.
This is, to our knowledge, something nobody else has done for POSIX-based agent memory. Not Karpathy's Wiki (no explicit filesystem-level relationships between entries). Not GBrain (relationships live in PostgreSQL, not the filesystem). Not Obsidian (wikilinks are text references in markdown, not
filesystem-level pointers).
The symlink approach is the design choice that makes everything else possible.
SMF organises memory into 8 entity types, each stored as a directory:
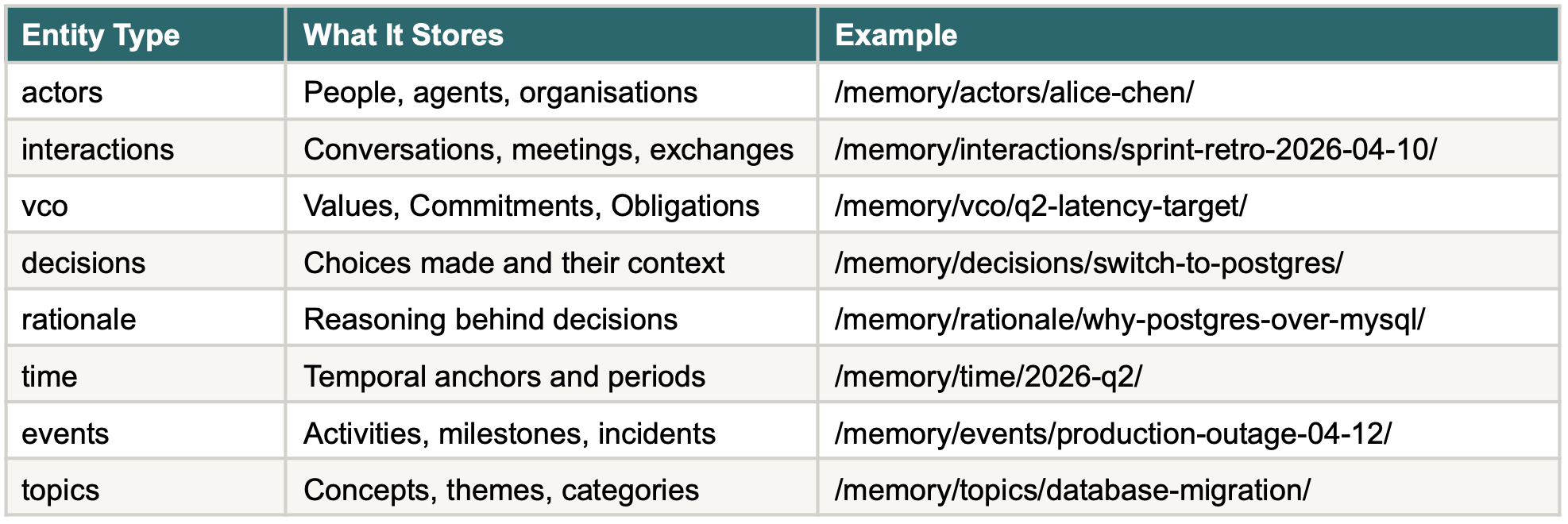
8‑type ontology table as in current blog
Why these 8 and not 6 or 12? Because they are the minimal set that closes the organisational utility function: who (actors), what happened (interactions, events), what was decided (decisions), why (rationale), what was committed (VCOs), when (time), and about what (topics). Remove any one and you lose a question type that organisations routinely need answered. Add more and you introduce categories that can be composed from these primitives. The taxonomy is opinionated, and deliberately so.
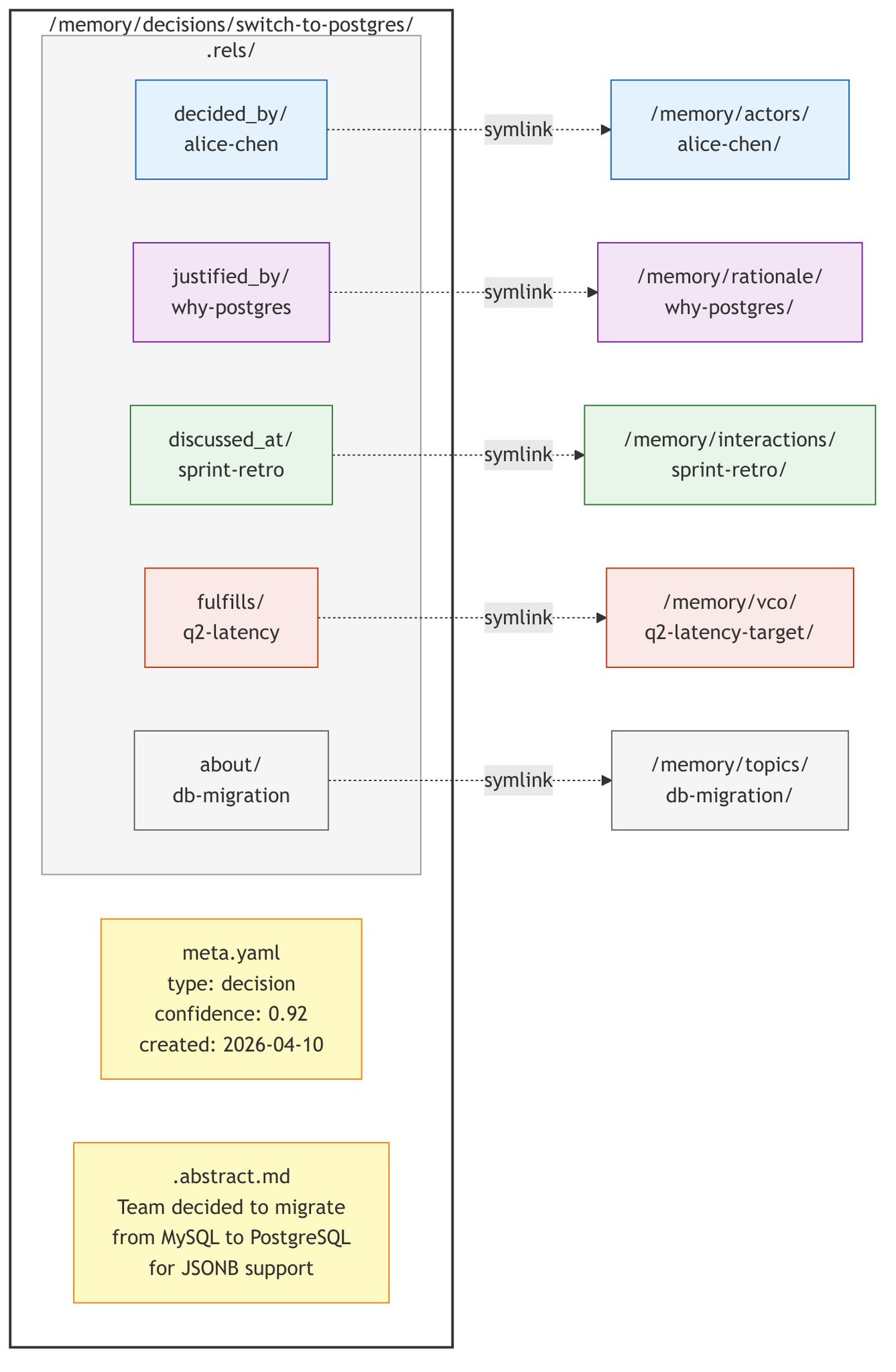
A single SMF entity on disk: metadata, abstract and typed symlinks forming the knowledge graph.
Each entity is a directory containing content.md (canonical content), meta.json (structured metadata), a related/ subdirectory containing symlinks to related entities, and .provenance.jsonl capturing how the entity was produced. The symlinks are typed: collaborated_with, decided_at, updates, contradicts, derives, extends. The filesystem itself encodes the knowledge graph. No external graph store. No separate schema DSL. No GraphQL endpoint. Just directories, files, and symlinks.
Think about what this means operationally. An agent that needs to understand the context around a decision can ls /memory/decisions/switch-to-postgres/related/ and immediately see every related entity: the actors involved, the rationale, the meeting where it was discussed, the commitment it fulfilled. No embedding lookup. No graph traversal engine. No LLM call. Just a directory listing. The graph is inspectable with tools that predate the internet.
Where SMF surpasses knowledge base approaches: scalability and access control
This architectural choice, symlinks as graph edges, gives SMF two properties that no knowledge base approach can match natively.
Scalability without context window dependence. Karpathy's Wiki works at ~100 articles because the LLM can read index files and navigate. GBrain works at 10{,}000+ files because PostgreSQL handles the search. Obsidian based systems degrade when the vault outgrows the context window. SMF's symlink graph has no such ceiling. Traversal is readlink and ls, kernel-level operations that work at millions of entries. The graph does not need to fit in a context window to be navigable.
And as of April 7, 2026, scalability takes another leap. Amazon S3 Files delivers native POSIX filesystem semantics on S3 buckets: mount via NFS v4.2, perform standard file operations, with POSIX permissions preserved as S3 object metadata. This means SMF's entire symlink-based knowledge graph can run on S3: effectively infinite storage at $0.023$/GB-month, 11 nines of durability, concurrent access from up to 25,000 compute resources, and the same ls -la inspectability.
Practical grounding: what happens at real scale. Symlink creation on POSIX is atomic; there are no partial states and no write conflicts at the filesystem level. Stale symlinks are detected and pruned by the gardener cycle during META-REFLECT. Dangling symlinks are a feature of POSIX, not a bug: readlink
returns the target path whether or not the target exists, so traversal does not crash on a stale edge.
Native access control. Unix file permissions, chmod, chown, ACLs, apply to every entity directory and every symlink in SMF. An entity can be readable by one team and invisible to another. SMF implements 4 sensitivity levels (public, internal, confidential, restricted) with identity-based access and section-level redaction. This is not a feature bolted on top. It is a natural consequence of using the filesystem as the storage layer. POSIX gave us access control for free.
How it works: brain-like, not by metaphor
The symlink web in SMF, with its confidence-weighted edges, shortcut creation, and zone-based forgetting, mirrors three well-documented properties of biological memory:
Synaptic strengthening. When two memories are accessed together, SMF can create or strengthen shortcut symlinks between them, reducing the hop count for future traversal. This is the filesystem equivalent of Hebbian learning: neurons that fire together wire together.
Memory consolidation and zones. SMF implements a zone-based lifecycle (hot → warm → cold) governed by Bjork's New Theory of Disuse, which models memory strength as two independent quantities: storage strength (how well something is encoded) and retrieval strength (how accessible it is right now). Retrieval strength decays with disuse; storage strength does not.
Pruning. SMF's gardener cycle prunes weak edges and demotes low confidence facts, analogous to synaptic pruning during sleep. Memories that have not been accessed for extended periods gradually become inaccessible without being destroyed. This is forgetting done right: not deletion, but deprioritisation.
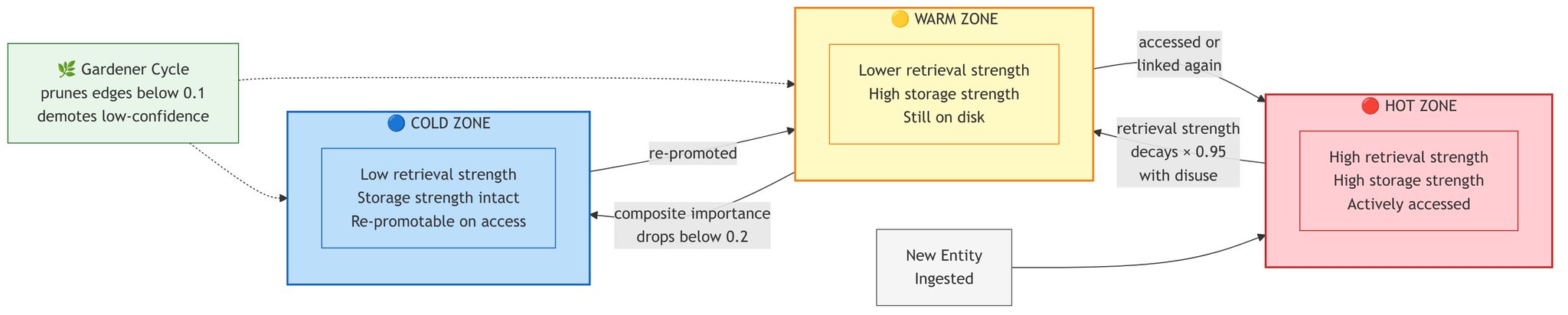
Zone-based memory lifecycle: hot to warm to cold with dual-score model.
Knowledge bases do not forget. They should not; that is their job. But memory systems must, because unbounded accumulation without relevance decay is not memory. It is hoarding.
The six-stage pipeline: from conversation to knowledge graph
SMF processes raw conversations through a 6-stage pipeline that progressively transforms unstructured text into a connected knowledge graph:
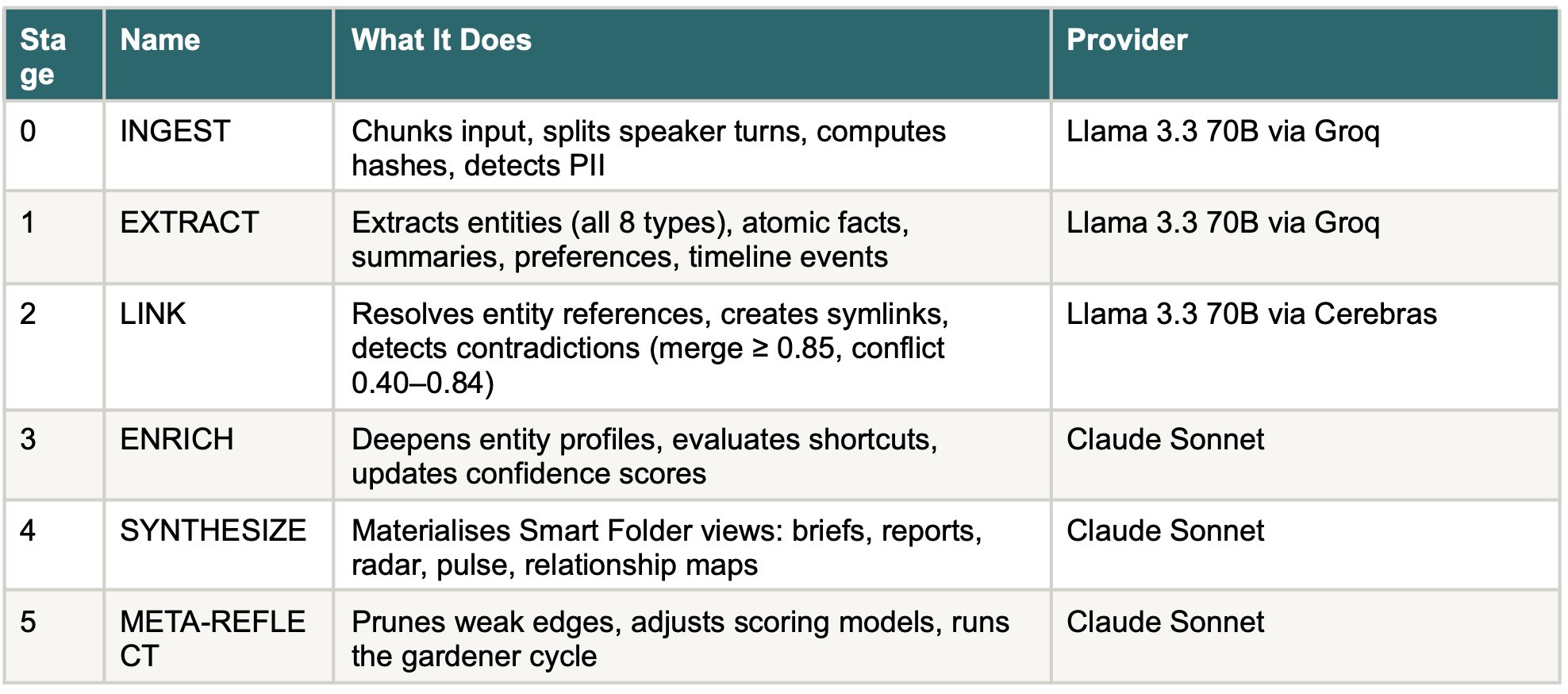

The 6-stage pipeline: fast models handle extraction, frontier models handle reasoning.
The pipeline is asymmetric by design. Stages 0–2 use fast, cost-effective models for high-throughput extraction and linking. Stages 3–5 use frontier models for reasoning-heavy enrichment and reflection. In the LoCoMo benchmark configuration, Stages 4 and 5 are disabled; the architecture is present, but the pipeline stops after Stage~3 for evaluation.
The LINK stage is the critical one: it resolves entity references (merge threshold ≥ 0.85, conflict range 0.40–0.84), creates typed bidirectional symlinks, and grows the knowledge graph with every ingested conversation. A 30-alias normalization layer handles the inevitable inconsistency in LLM-generated entity types.
The retrieval architecture: 14 channels, not 4
This is where the open-source release goes substantially beyond the original four-channel story. The canonical pipeline began with BM25, embeddings, graph traversal, and temporal filtering. The actual system implements 14+ channels, all fused through Reciprocal Rank Fusion and routed by query mode:


Three-layer retrieval: parallel channels → RRF → agentic ReAct loop → Self-RAG validation.
The system detects query intent and routes to different channel weightings depending on the query type. Seven query modes, factual, temporal, counting, multi-session, preference, summarisation, contradiction, each have custom RRF weight profiles.
On top of the parallel retriever sits an agentic retriever: a ReAct loop with 9 tools that runs up to 5 iterations and short-circuits at 0.75 confidence. Post retrieval, Self-RAG validation can verify the generated answer claim-by-claim against retrieved sources.
Why benchmarking memory is fundamentally hard
We return to the utility function problem, because it is the lens through which every number below must be read.
Every memory benchmark implicitly defines a utility function. LoCoMo asks questions about long-form conversations. These are good questions that test retrieval accuracy, one axis of memory quality. But retrieval accuracy is not the only axis. A memory system that retrieves perfectly but cannot enforce access control is unusable in an enterprise.
The Golden Gate Bridge problem from earlier applies directly: LoCoMo's utility function determines which answers count as correct. A benchmark that tested relational durability, access control, contradiction handling, or lifecycle management would produce a different ranking. No such benchmark exists yet.
With that stated clearly, here are the numbers, as we believe they should be reported.
Benchmark results: structure over scale
Retrieval architecture and memory structure matter more than model scale.

We evaluate SMF on the LoCoMo benchmark with a dedicated GPT‑4.1 judge independent of the QA model, using strict prompts that require matching the same core fact and meaning, not just “touching the same topic”. Earlier self-judged runs (where the QA model graded its own answers) produced inflated J-scores and are omitted here except where noted as mechanical F1.
A representative slice (1 conversation, 199 QA pairs) looks like this:
A roughly 50× increase in model scale (8B → Sonnet) moves J-score by only 0.081 under a strict, dedicated judge. The architecture, the filesystem-native graph, temporal index, fact store, BM25, and retrieval pipeline, remains the same.
Even more striking is the retrieval ablation:
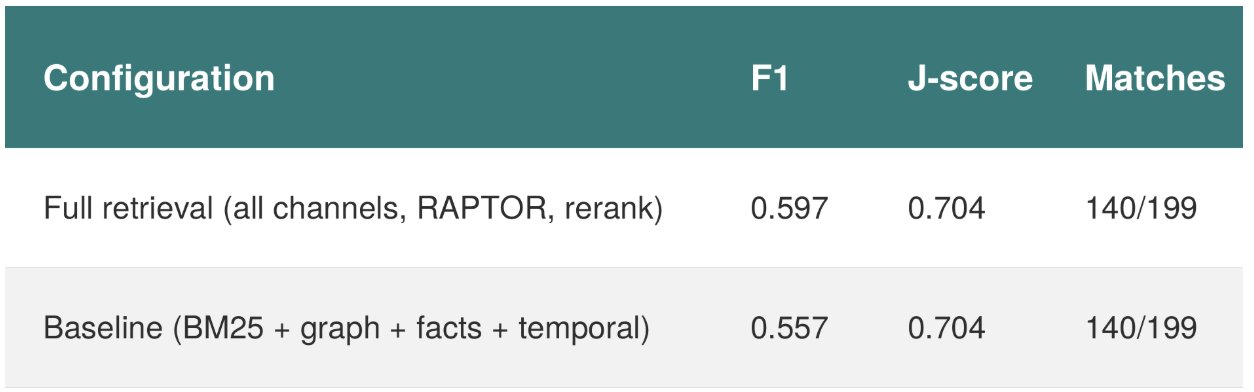
The baseline configuration disables dense embedding search, RAPTOR hierarchical summaries, hierarchical/agentic retrievers, the Retrieval Reflector, self-RAG validation, and cross-encoder reranking. It keeps only BM25 (entities and facts), graph traversal, and a temporal index. J-score and match counts are identical. There is a shared core of 149 questions where both configurations agree; the remaining questions are traded between them.
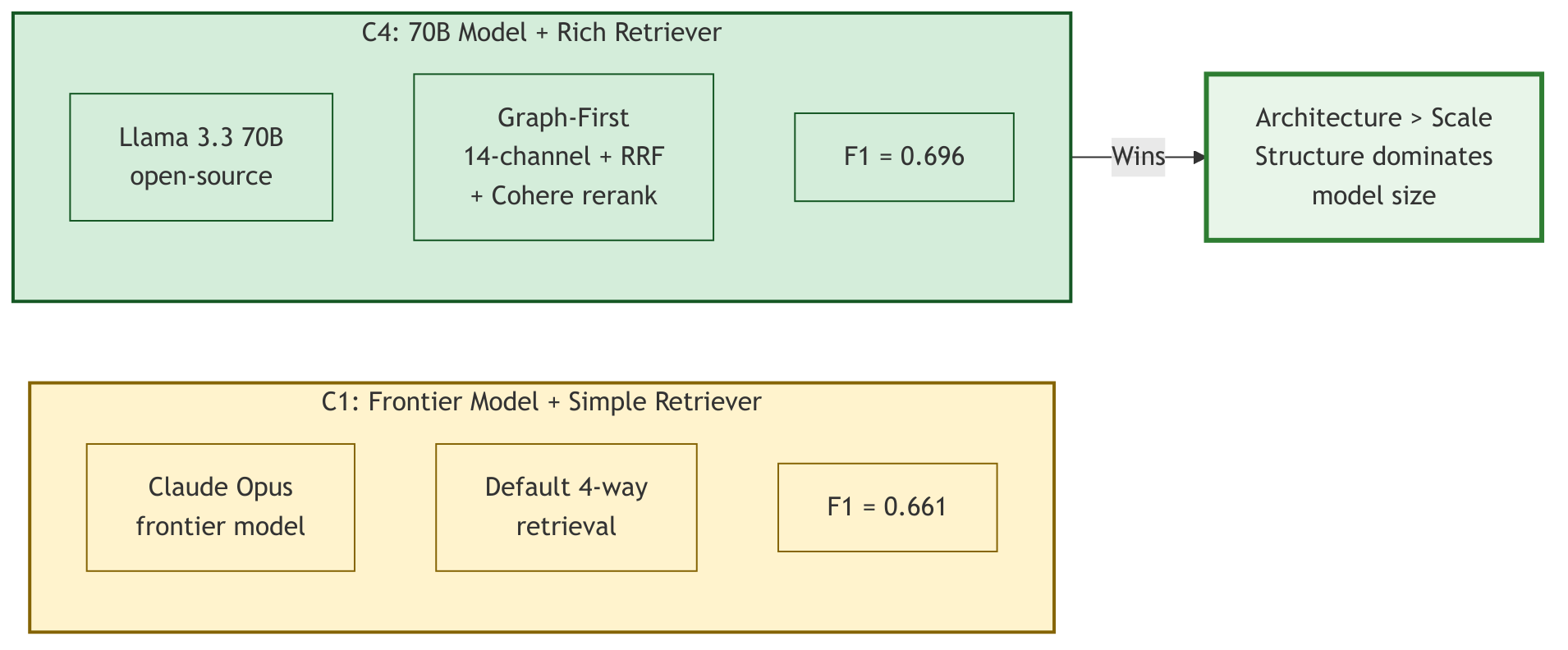
The structure-over-scale punchline: C4 (70B + rich retrieval) beats C1 (frontier + simple retrieval).
In other words: a deployment that \emph{only} uses BM25 + symlinks + temporal can match the aggregate strict J-score of a full 14+ channel stack. Organisations can choose retrieval complexity as a function of their workload: full stack for open-domain heavy workloads, baseline for precision-oriented multi-hop, or something in between.
Comparison against the field
Let us be honest about where we stand.
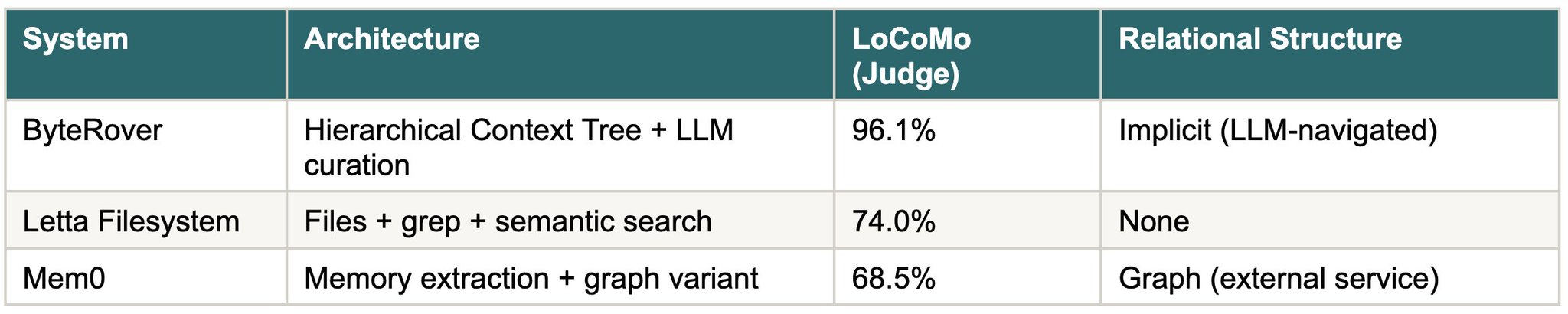
Systems evaluated with LLM-as-Judge on LoCoMo
Systems evaluated with token-level F1 on LoCoMo

Systems not benchmarked on LoCoMo

ByteRover achieves higher raw benchmark scores. We are not going to pretend otherwise. But there is a distinction worth making between benchmark performance on one test and architectural properties that determine long-term behaviour.
SMF's relationships are explicit and non-parametric. The symlink from actors/alice/.rels/collaborated_with/bob to actors/bob/ exists on disk. It survives model changes. It is traversable without an LLM call. ByteRover's relational knowledge is parametric, reconstructed at inference time.
Under lenient judging, large systems report J-scores in the 88–96% range on LoCoMo. Under the strict judge we use, SMF lands around 70% J on the same tasks, and so do other systems when re-evaluated through safer prompts and stricter judges. We do not pretend that J=0.704 is the highest number in the ecosystem. We do claim that it is a more honest number.
The more important distinction, for us, is structural:
SMF's relationships are explicit and non-parametric. The symlink from actors/alice/related/collaborated_with/bob to actors/bob/ exists on disk. It survives model changes. It is traversable without an LLM call.
Many competing systems store relational structure parametrically inside model weights or in opaque graph stores. Their relations are reconstructed at inference time rather than inspected directly.
What we are open-sourcing
The repository at https://github.com/dynamis-Labs/SMF contains the core of SMF:
The full 6-stage pipeline (0-indexed: INGEST through META-REFLECT)
All 8 entity types with Pydantic models, subtype schemas, and alias table
The parallel retriever with 14+ channels and RRF fusion
The agentic retriever (ReAct loop, 9 tools, max 5 iterations)
7 query modes with per-mode channel routing and weight profiles
Self-RAG validation hooks for claim-by-claim checking
The lifecycle subsystem: gardener, garbage collection, zone management with Bjork's New
Theory of Disuse (disabled in current benchmarks, implemented in code)
Security and ACL: 4 sensitivity levels, identity-based access, section-level redaction
An MCP server with 12 tools, 5 resources, and 4 prompts for agent integration
Circuit-breaker inference routing across multiple providers (Groq, Cerebras, Claude, OpenAI,
Gemini, Modal)
We are not releasing everything. The production system adds capabilities specific to error correction, multi-tenant organisational deployment, cross-organisation memory isolation, advanced lifecycle tuning, and integrations with enterprise communication channels. The open-source release is the architecture and the core pipeline. The production system is where it becomes a product.
What comes next
Forgetting and false recall are the price of meaning. SMF does not claim to have escaped that tradeoff. It claims to be a principled navigation of the frontier. The filesystem provides exact episodic storage. The semantic layer provides generalisation, analogy, and conceptual transfer. The symlinks bridge the two: they are simultaneously exact (a symlink either exists or it does not) and semantic (the relationship types encode meaning).
The brain does something similar. Fast hippocampal encoding creates episodic records. Slow neocortical consolidation extracts semantic structure. SMF's architecture mirrors this interplay, not as a metaphor, but as a structural implementation: rapid ingestion through the fast-model stages (0 2), slower enrichment and synthesis through the frontier-model stages (3–5), and continuous maintenance through the gardener and zone manager.
The question the field should be asking is not “How do we build a better knowledge base?” It is: “What does this agent need to remember, and why?” The answer to that question is a utility function. And the best memory systems are the ones that encode it structurally rather than leaving it to the model to figure out at inference time.
At Sentra, that utility function is the collective memory of a company: who decided what, when, why, and what was committed. The entity types, the symlink schemas, and the lifecycle management are all in service of that specific purpose, because an organisation that cannot remember what it committed to is an organisation that cannot be held accountable.
Code: https://github.com/dynamis-Labs/SMF
SpectralQuant: https://github.com/Dynamis-Labs/spectralquant
The Geometry of Forgetting: https://arxiv.org/abs/2604.06222
The Price of Meaning: https://arxiv.org/abs/2603.27116
This is the fifth in a series. SpectralQuant showed that 97% of dimensions are noise and exploited the spectral gap for compression gains. The Geometry of Forgetting showed the same spectral concentration governs memory failure. The Price of Meaning proved the failure is inescapable. SMF is the architectural response. Same eigenvalue spectrum, four different consequences: compression, attention, the mathematical limits of memory, and now the system that takes those limits seriously. All grew out of the research program at Sentra, where we are building enterprise general intelligence: a shared AI layer that sits on all communication channels and agent traces to understand how everyone in an organization actually works and how work actually gets done, constructing a living world model of the entire company in near real time.