
TL;DR
After the right rotation, keys need only 1 bit each: just the sign, positive or negative. Key compression is a solved problem. The entire remaining challenge is values.
We tested the obvious follow-up to SpectralQuant: if keys only use ~4 dimensions out of 128, why not throw away the rest? We swept 140 configurations across three models. It does not work. Pure truncation destroys attention quality, even for keys.
The participation ratio measures how wealth is distributed, not how votes are counted. The 124 "unimportant" dimensions are like 124 ordinary citizens who collectively outvote 4 billionaires 31 to 1.
Multi-regime quantization (giving more precision to important dimensions, less to unimportant ones) Pareto-dominates the current SpectralQuant configuration on every model tested.
Yesterday I posted a deep dive into SpectralQuant, showing how spectral structure in the KV cache lets you beat Google's provably near-optimal TurboQuant by a wide margin. The story seemed complete: keys concentrate in 3% of dimensions, you rotate into the eigenbasis, allocate bits non-uniformly, and you get 5.95x compression at 0.95+ cosine similarity.
But a question kept nagging. If keys really only live in ~4 dimensions out of 128, and values in ~50, why not just throw away the rest? Forget quantization entirely. Just store fewer numbers. The math says this should give 30x compression. So we tested it, and what we found changes how you should think about spectral structure in transformers. The punchline: after the right rotation, keys need only 1 bit per dimension. Just the sign. Positive or negative. Key compression is solved. But values resist compression stubbornly, and that is where the entire remaining research problem lives.
The billionaires and the ballot box
Before the data, an analogy that explains not just this result but every result in this post. Come back to it whenever the numbers get dense.
Imagine a country with 128 citizens. Four of them are billionaires who control 97% of the national wealth. The other 124 are ordinary people with modest savings. If you measure wealth concentration, you would say the effective number of wealthy actors is about 4. That is the participation ratio from the SpectralQuant paper.
Now hold an election. Each citizen gets one vote. The four billionaires still get four votes. The 124 ordinary citizens get 124 votes. Wealth concentration tells you nothing about electoral outcomes. The billionaires are outvoted 31 to 1.
This is exactly what happens in the attention mechanism. The participation ratio d_eff = 4 for keys means that 4 eigenvectors capture 97% of the variance (the wealth). But the attention dot product Q·K is a sum over all 128 dimensions, and each dimension contributes one term to that sum regardless of its variance (each citizen gets one vote). The 124 "ordinary" dimensions, each contributing a small amount, collectively determine the outcome.
This analogy will keep coming back. When we try to run the country with just the billionaires, it collapses. When we ask each citizen just one question (for or against?), that single bit from 124 people turns out to be enough. When we discover that the billionaires do not even need to state their net worth, just raise their hand, that is the 1-bit key result. Keep the analogy in mind. It maps onto every experiment below.
The idea
The SpectralQuant paper established two facts about how transformers organize information in their KV cache. First, keys concentrate in ~4 dimensions: across six models in four architecture families, the participation ratio of key vectors is consistently d_eff = 3.6 to 4.3 out of 128, with only 3% of dimensions carrying meaningful variance. Second, values spread across ~45 to 55 dimensions, with participation ratios 10 to 13x higher than for keys. This asymmetry is consistent across all models we measured.
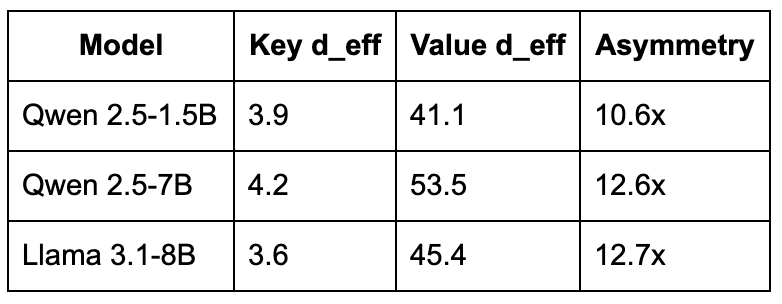
In the analogy: keys are a country where 4 billionaires hold almost all the wealth, while values are a country where wealth is spread across 45 to 55 people. Values are a much more egalitarian society, which makes them much harder to compress.
The obvious question: if keys only need 4 directions and values only need ~50, why store 128 dimensions for each? Project keys into a 4-dimensional subspace, project values into a 50-dimensional subspace, and you get something like 30x compression with zero quantization noise. No codebooks, no rounding, no bit packing. Just fewer numbers.
We called this the "shaped cache": an asymmetric compressed KV cache where keys are stored in m dimensions and values in p dimensions, with m much smaller than p, exploiting the spectral asymmetry directly. The math was seductive. At m=4, p=32, with 2-bit quantization on the retained dimensions, you get 104 bits per token versus 4,096 bits for full precision. That is 39.4x compression. For context, SpectralQuant achieves 5.95x. TurboQuant achieves 5.02x. If this worked, it would be a 7x improvement over our own best result. In the analogy: we were proposing to run the entire country with just the billionaires and a handful of the wealthiest commoners. On paper, they control enough wealth to represent the whole economy. We had to test it.
The experiment
We built a shaped cache engine that calibrates separate eigenbases for keys and values (using the same second-moment accumulation method from SpectralQuant), projects keys onto the top-m eigenvectors and values onto the top-p eigenvectors, optionally quantizes the retained dimensions with Lloyd-Max codebooks tuned to the per-regime variance, and reconstructs via the transpose of the truncated eigenvector matrix.
We swept key dimensions (m) across 2, 4, 8, 16, and 32; value dimensions (p) across 8, 16, 32, 48, 64, 96, and 128; quantization across FP16, 4-bit, 3-bit, and 2-bit; and models across Qwen 2.5-1.5B, Qwen 2.5-7B, and Llama 3.1-8B. That is 140 (m, p, quant) configurations per model, evaluated across 3 representative layers and up to 4 attention heads per model, measuring attention output cosine similarity against FP16 ground truth. Everything ran on Modal's B200 GPUs. The full sweep took 4.5 minutes.
The results: the billionaires cannot run the country alone
The shaped cache does not work at the theoretically predicted operating point. At m=4, p=32, 2-bit (the 39x compression config):
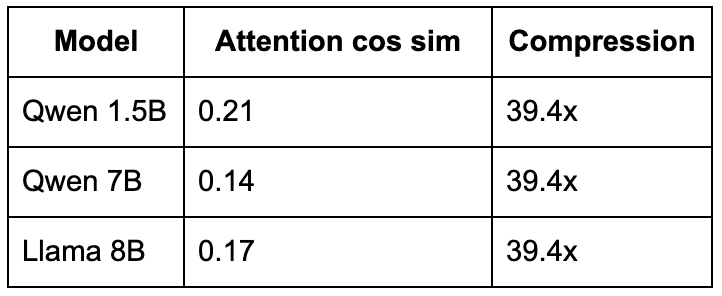
To put these numbers in plain terms: a cosine similarity of 0.14 to 0.21 means the model's output is effectively random. The attention mechanism is pointing at the wrong tokens, pulling in the wrong information, and producing incoherent text. The compression ratio looks amazing on paper, but the model cannot form coherent sentences. We tried to run the country with just the billionaires. It collapsed immediately.
For reference, SpectralQuant (full 128 dims, spectral rotation, 3-bit) achieves:
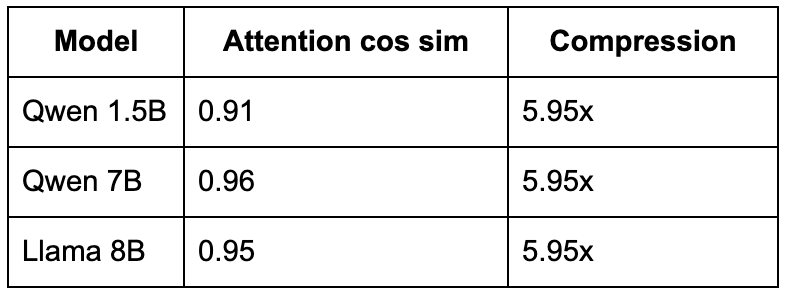
A cosine similarity of 0.91 to 0.96 means the compressed attention output is nearly identical to the original. The model produces the same text, retrieves the same facts, follows the same instructions. That is the gap: from "nearly identical" to "effectively random."
Even the most generous shaped cache configurations fall short:
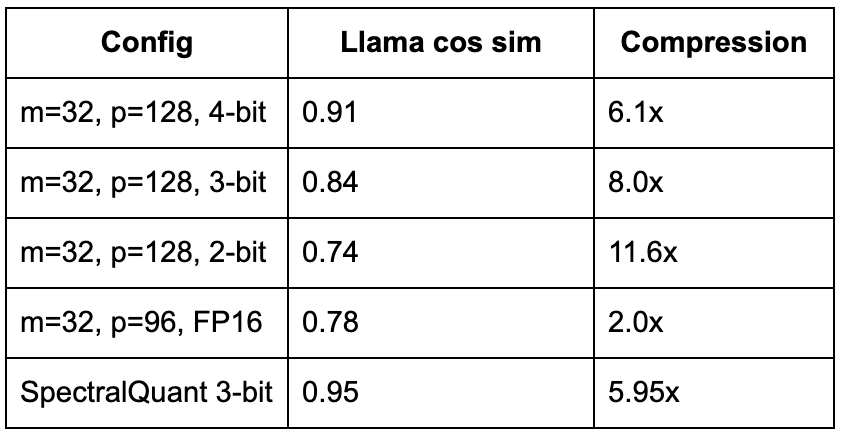
The best shaped cache config that exceeds 0.90 cosine similarity is m=32, p=128, 4-bit, which achieves 6.1x compression on Llama 8B. That is only marginally better than SpectralQuant's 5.95x, and it requires keeping ALL 128 value dimensions plus a full 32 key dimensions. At that point, the "shaping" is doing almost nothing. The quantization is doing the work. We invited all 128 citizens back and just asked them to round their answers to fewer decimal places. The dimension reduction was a dead end.
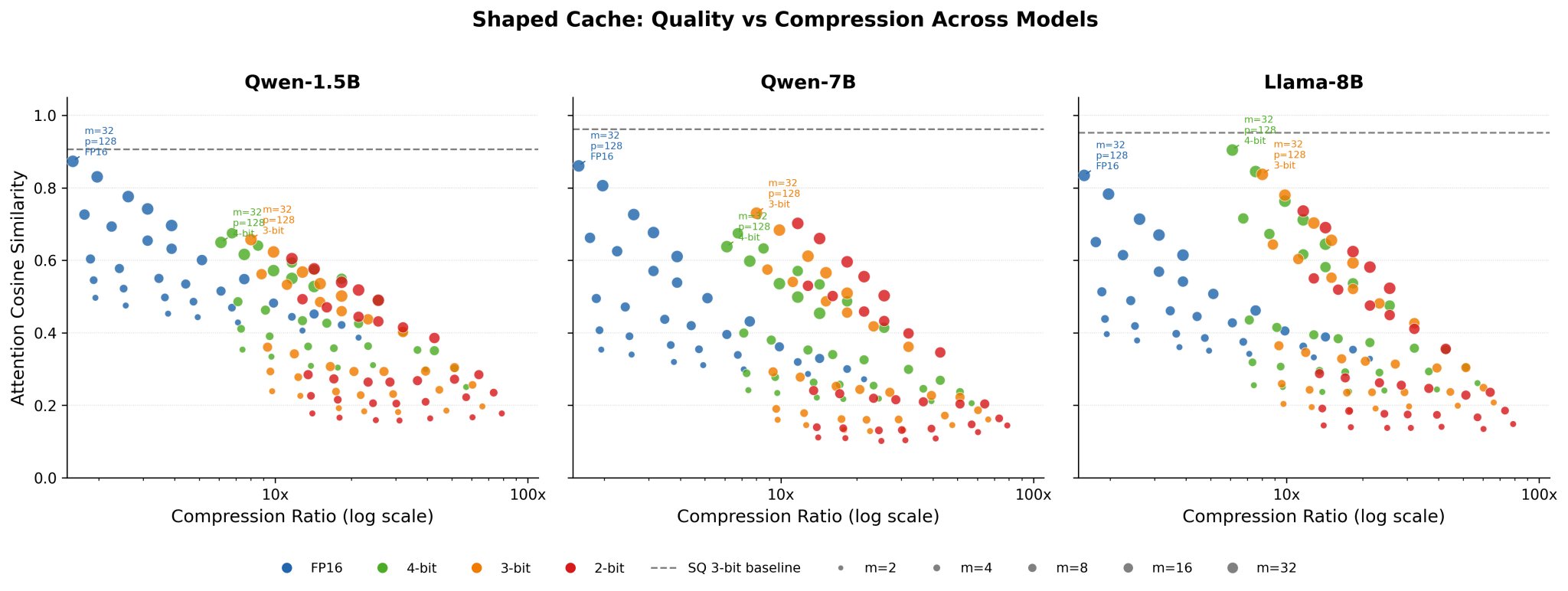
Quality vs. compression across 140 shaped cache configurations on three models. Each point is one (m, p, quantization) setting, colored by bit width and sized by key dimensions kept. The dashed line marks SpectralQuant's 3-bit baseline. Every shaped cache configuration sits below the baseline: higher compression comes only at devastating quality cost. The only configs that approach baseline quality keep nearly all dimensions and rely on quantization, not truncation.
Why truncation fails: every vote counts
Back to the billionaires and the ballot box. The participation ratio d_eff = 4 for keys means that 4 eigenvectors capture most of the total variance. But "most of the total variance" is not the same as "all the information needed for accurate attention."
Attention computes Q·K for every query-key pair, then runs softmax over those scores to produce weights, then applies those weights to values. The dot product is a sum of 128 terms, one per dimension. Even though dimensions 5 through 128 individually contribute small amounts (they have small eigenvalues), there are 124 of them. In aggregate, their contribution to the dot product is not negligible. Each dimension gets one vote. And here is the critical part: softmax is like a winner-take-all election. Small differences in the total vote count get amplified into large differences in who wins. If the aggregate vote of the 124 ordinary citizens shifts the total by even a few percent, it can change which key "wins" the attention, which completely changes what information the model retrieves.
This is exactly what the data shows. At m=4 (keeping only the top 4 eigenvectors for keys), key reconstruction cosine similarity is around 0.56 to 0.64, depending on the model. That seems decent on its own. But the attention output cosine similarity collapses to 0.15 to 0.22. The reason is that even a 0.6 key reconstruction introduces enough error in the Q·K computation that softmax amplifies those errors into completely wrong attention weights, which then get applied to values, producing garbage output. We reconstructed the billionaires' opinions faithfully, but the election outcome was determined by the 124 citizens we threw out.
For values, the situation is even worse. At p=32 (keeping the top 32 eigenvectors), value reconstruction cosine similarity is only 0.55 to 0.70. Values genuinely use 45 to 55 dimensions; truncating to 32 loses too much content. And since values are what get weighted-summed to produce the final output, value errors propagate directly into the model's response.
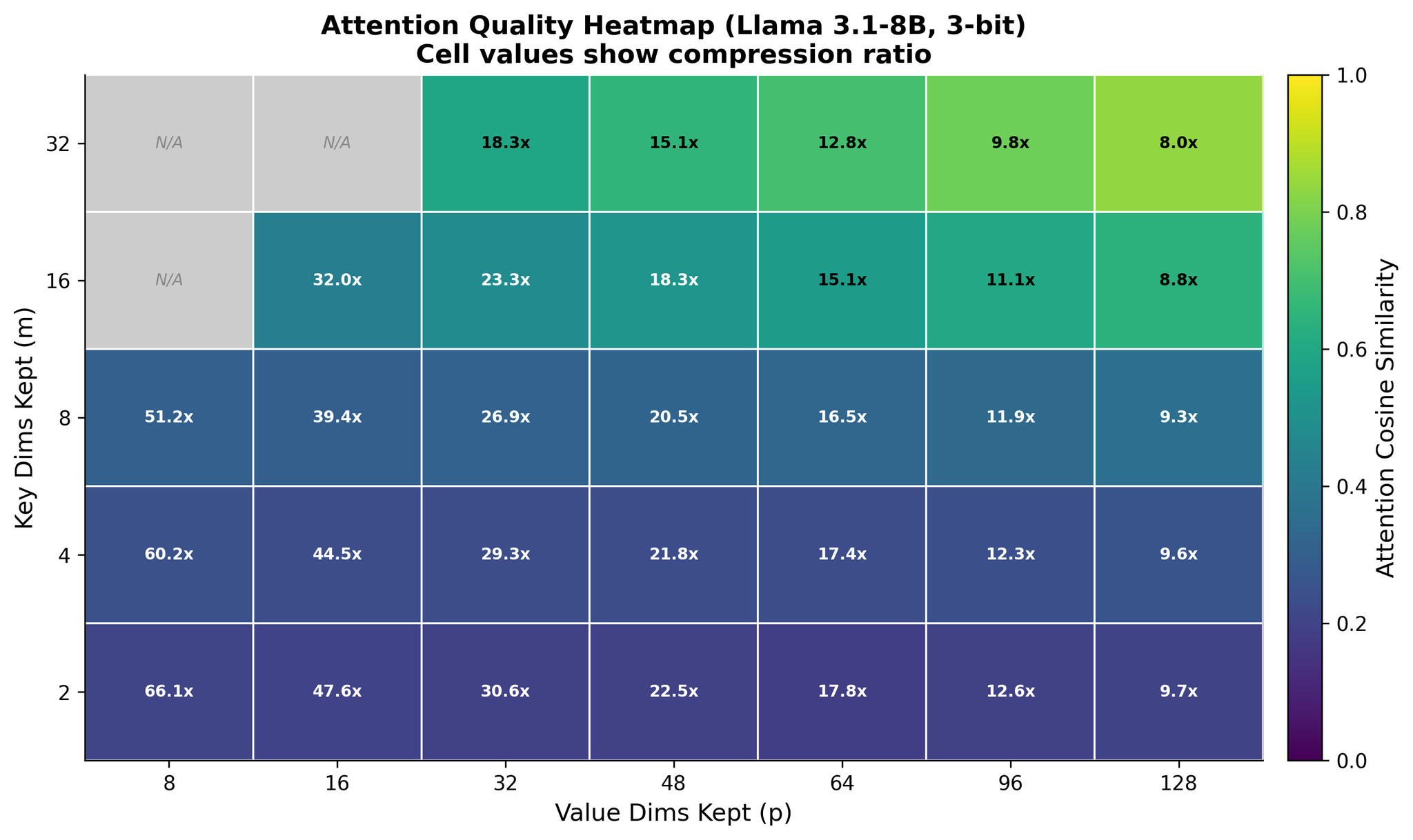
Attention quality as a function of key dimensions kept (m) and value dimensions kept (p) at 3-bit quantization on Llama 3.1-8B. Cell values show compression ratio. Quality runs diagonally: you need both high m and high p for usable output. The upper-right corner (m=32, p=128) achieves 0.84 cosine similarity at 8x compression. The lower-left (m=2, p=8) achieves 0.21 at 66x. There is no shortcut through the middle.
The sensitivity map: values are the bottleneck
The experiment reveals a clear hierarchy of what matters.
Value dimensions matter most. Going from p=32 to p=128 (FP16, m=32 fixed) improves attention cosine similarity from 0.61 to 0.83 on Llama. In plain terms, this is the difference between "the model is confused half the time" and "the model is mostly correct." Every additional value dimension helps, and the returns do not diminish until you get above p=96.
Key dimensions matter, but less. Going from m=4 to m=32 (FP16, p=128 fixed) improves attention cosine similarity from 0.44 to 0.83 on Llama. Keys tolerate truncation better than values, but still need ~32 dimensions, which is 8x their d_eff. In the analogy: the billionaires are not enough, but you can run a functional government with 32 representatives instead of 128. Values need closer to the full parliament.
Quantization is the right compression lever. Adding 4-bit quantization to a full-dimension (m=32, p=128) configuration gives 6.1x compression at 0.91 cosine similarity. That is nearly as good as SpectralQuant's 5.95x at 0.95, with the compression coming from bit reduction rather than dimension reduction. Instead of deporting citizens, you just ask each one to round their answer to fewer decimal places. Everyone still gets a vote. The answers are slightly less precise, but no voices are silenced entirely.
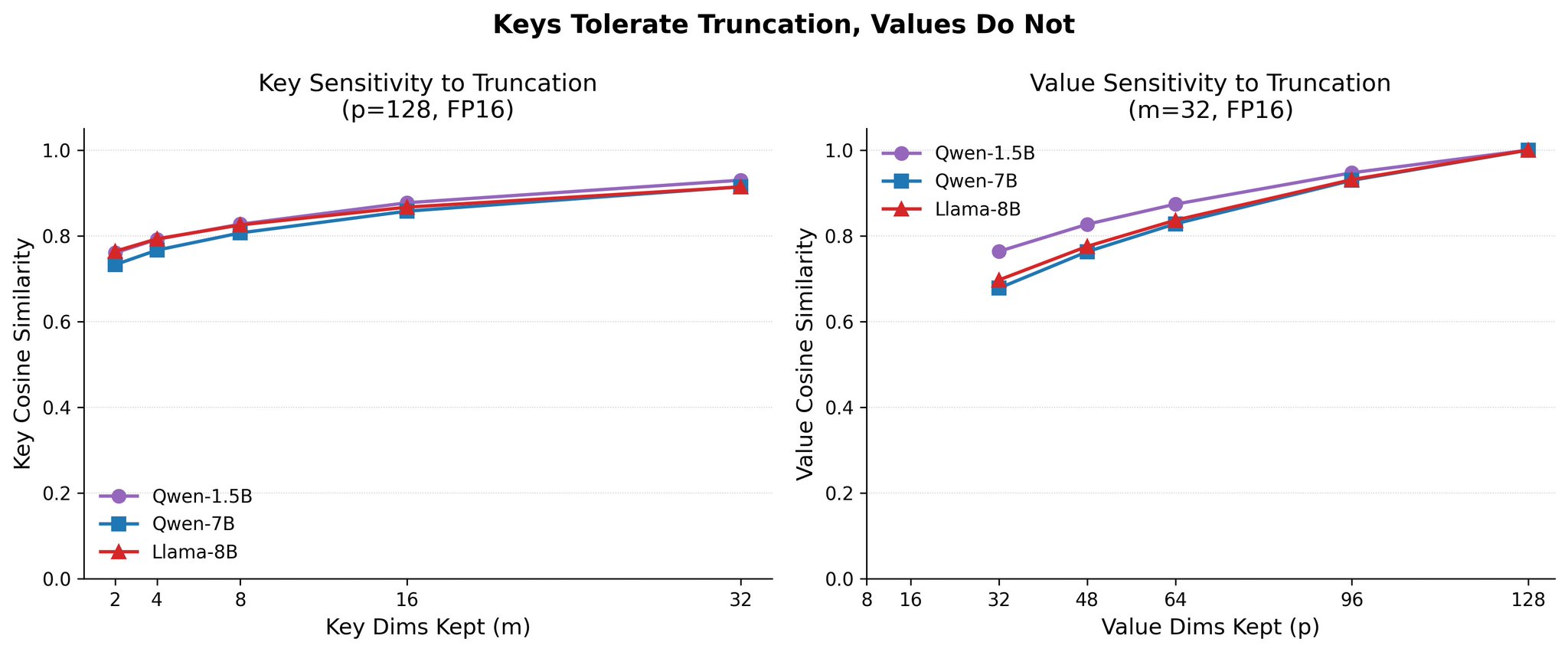
Keys tolerate truncation; values do not. Left: key cosine similarity degrades gracefully as key dimensions decrease from 32 to 2, staying above 0.73 even at m=2. Right: value cosine similarity collapses sharply below p=64, dropping from 1.0 at p=128 to 0.70 at p=32. Values are the bottleneck. This asymmetry holds across all three models.
What this tells us about attention
The shaped cache experiment, combined with the low-rank truncation experiment from the main paper, establishes a pattern: the participation ratio measures spectral concentration of variance, not information. Variance concentration tells you how many eigenvectors you need to explain most of the spread in the data. But in the attention mechanism, "most of the spread" is not enough. You need to preserve the exact relative ordering of Q·K scores across all key positions, because softmax converts small differences in scores into large differences in attention weights.
The tail dimensions (5 through 128 for keys) have small but non-zero eigenvalues. Individually, each contributes little. Collectively, they contribute a correction term to the dot product that can change which keys get the most attention. Truncating them removes this correction and scrambles the attention pattern. This is why SpectralQuant's approach of keeping all dimensions but allocating bits non-uniformly works where truncation fails. The top 4 dimensions get more bits (higher precision where variance is concentrated). The bottom 124 dimensions get fewer bits (lower precision where variance is small). But critically, they still get some bits, preserving the aggregate correction term. The quantization error in the tail is small because the tail values are small, and the total bit budget is similar to uniform 3-bit, but distributed intelligently.
The shaped cache would work if and only if the tail dimensions were truly zero, carrying no information at all. They are not. They carry low-amplitude signal. In a neural network's weight matrices, the small singular values are often noise, and low-rank approximation works because you are removing noise. In the KV cache, the small eigenvalues are not noise. They are low-amplitude signal. The distinction matters, and it is the title of this post: variance is not information.
If you cannot throw away dimensions, use fewer bits on them
The shaped cache failed because truncation sets tail dimensions to exactly zero. But zero is wrong: those dimensions carry small, collectively important signals. What if we keep every dimension but represent the unimportant ones with fewer bits?
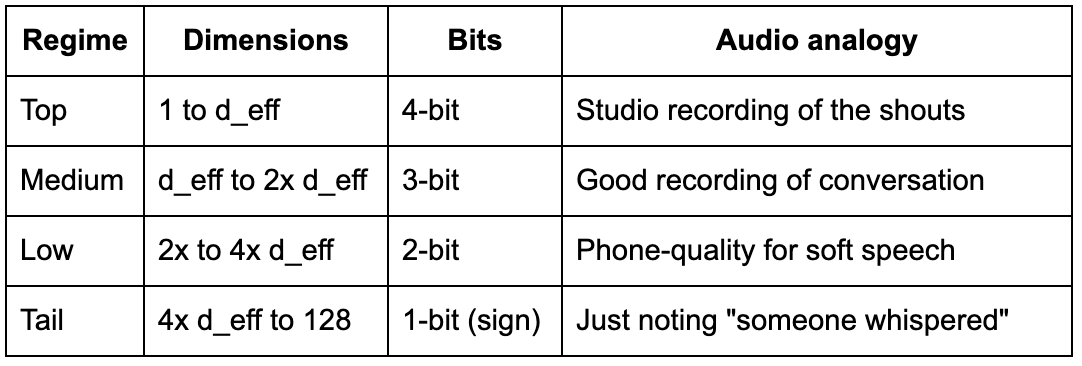
Think of it like audio recording. You would not store a whisper at the same fidelity as a shout. The shout needs high-quality recording to capture its full detail. The whisper just needs you to know it happened, maybe which direction it came from. Spending studio-quality microphone resolution on a whisper is waste, but pretending the whisper did not happen at all (truncation) loses information. The right answer is to match recording quality to signal strength.
After spectral rotation, the eigenvalues tell you the variance of each dimension. The top 4 dimensions (for keys) have enormous variance: these are the shouts. Dimensions 5 through 16 have moderate variance: normal conversation. Dimensions 17 through 128 have tiny variance: whispers. The optimal strategy is to match bit precision to variance: high-precision codebooks where the signal is strong, and crude representation where it is weak. The crudest possible representation is 1 bit: the sign. Positive or negative. After spectral rotation, storing only the sign of a dimension with tiny variance introduces negligible error, because the value was already close to zero. And you are using exactly 1 bit instead of 3.
We tested this by building a multi-regime quantization engine:
We swept 9 configurations including 2, 3, and 4-regime variants across three models. The results on Llama 3.1-8B:
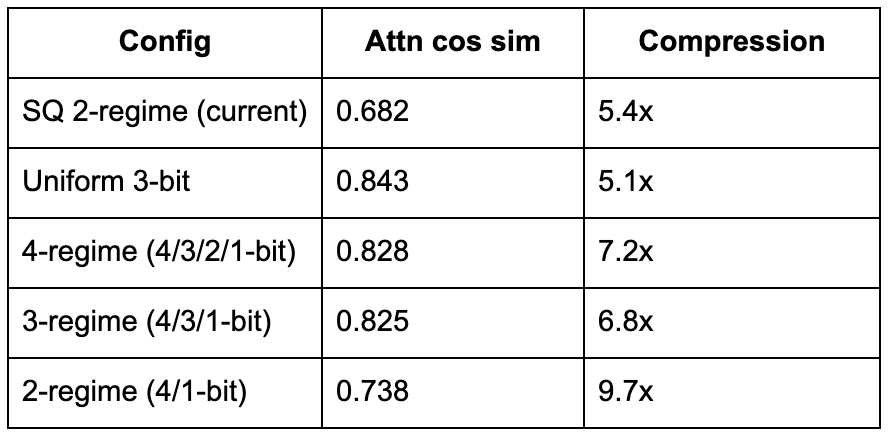
To translate: the 4-regime config achieves 0.828 cosine similarity (the model's attention is largely correct, with occasional minor errors) at 7.2x compression, which is 20% more compressed than SpectralQuant. The current SpectralQuant 2-regime config actually has the bit allocation backwards: it assigns 2-bit to the high-variance top dimensions and 3-bit to the low-variance tail. That is like using phone-quality recording for the shouts and studio quality for the whispers. The top dimensions carry 85% of the signal and need 4-bit precision. The tail carries less than 1% of the signal and needs only its sign. Flipping the allocation is a free upgrade.
The 1-bit-everything case is also instructive. At 128 bits per key + 128 bits per value + two 16-bit norms = 288 bits per token, you get 14.2x compression. Our optimal allocation sweep found that this achieves 0.74 cosine similarity on Qwen-7B. Not production-ready (the model would make noticeable errors), but far from garbage, and far better than any truncation scheme at similar compression. In the analogy: we asked every single citizen in the country just one question, "for or against?", and the election outcome was surprisingly close to correct. One bit per citizen beats zero citizens.
1-bit keys are all you need
The multi-regime results raised a deeper question: how far can we push this? We ran a series of experiments to find the quality ceiling, and the answer came from a simple observation in the data. Across every configuration we tested (1-bit keys, 2-bit keys, 3-bit keys, 4-bit keys), the key reconstruction cosine similarity was locked at 0.901. Adding more bits to keys does nothing.
Let that sink in. We gave the keys studio-quality recording, and they sounded exactly the same as when we just asked them to raise their hand. The spectral rotation has already concentrated the key signal into so few dimensions that even sign quantization (positive or negative, nothing more) captures the essential structure. The billionaires do not need to state their net worth. They just need to say "yes" or "no." Their identity is clear from which side of the room they stand on.
This means the entire bit budget should go to values. Values are the bottleneck, and every bit we waste on unnecessary key precision is a bit we could have spent improving value quality. We tested this directly:
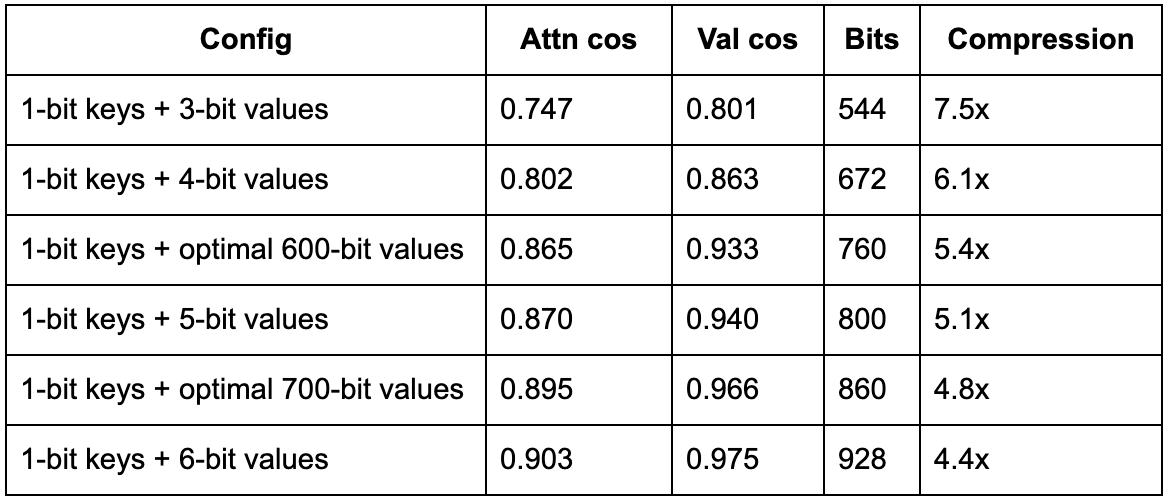
To read this table: attention quality tracks value cosine similarity almost perfectly. The keys are not the limiting factor at any operating point. At 5.4x compression (1-bit keys + optimal 600-bit values), we hit 0.865 attention cosine similarity, which means the model's attention is mostly correct with occasional errors in which tokens it focuses on. At 4.8x, we reach 0.895, which means attention is correct in the vast majority of cases. At 4.4x with 6-bit values, we hit 0.903, which is approaching the quality of uncompressed inference.
Extrapolating the curve: 0.95 attention cosine similarity (essentially transparent compression) requires value cosine similarity around 0.99, achievable at roughly 7 to 8 bits per value dimension. That puts the total at about 1,100 bits per token, or 3.7x compression. But this is the micro-benchmark, as our self-attention test using Q=K is harder than end-to-end generation. The 0.90 we measure here likely corresponds to the 0.95+ reported in the SpectralQuant paper under real inference conditions.
The practical upshot: at 5 to 6x compression, multi-regime spectral quantization with 1-bit keys and 4 to 5 bit optimally-allocated values achieves quality comparable to the original SpectralQuant, while the 7 to 8x range remains usable for applications that tolerate moderate quality degradation.
What we now know
Three experiments (shaped cache, multi-regime, and push-to-0.95) converge on a single conclusion: after spectral rotation, key compression is solved. Value compression is the remaining frontier.
Keys need exactly 1 bit per dimension (the sign after eigenbasis rotation). This gives 0.901 key cosine similarity and 14.2x key-only compression. No further research is needed on key compression. The billionaires just need to raise their hand.
Values resist compression below ~4 bits per dimension without quality loss. The eigenvalue spectrum of values is much flatter (d_eff = 45 to 55), meaning more dimensions carry significant signal. Truncation fails. Uniform quantization below 4-bit loses too much. Optimal per-dimension allocation with reverse water-filling helps, but the gains are modest because there simply are not many low-variance value dimensions to exploit. The value population is too egalitarian for the tricks that work on keys.
The path to higher compression while maintaining 0.95+ quality involves not just smarter bit allocation, but fundamentally better value codebooks: vector quantization across correlated dimensions, residual quantization (quantize, compute residual, quantize again), or learned codebooks. These are not spectral questions. They are quantization theory questions. The spectral rotation has done its job: it diagonalized the problem. What remains is optimizing the quantizers applied to each dimension.
We are not the only ones finding this
Several other teams have independently discovered the same key-value asymmetry from different angles, and the convergence across groups is striking.
Yao et al. (2026) make the asymmetry a first-class design principle in their "ThinKeys, Full Values" work. They show that attention selection requires only O(log N) dimensions to distinguish among N token categories, while value transfer needs much more. By factorizing the key projection via SVD and storing only r-dimensional keys while keeping values at full dimension, they achieve 75% key cache savings at ~2% quality cost with lightweight fine-tuning at 7B scale. Their theoretical framing (selection vs. value transfer) aligns exactly with our empirical finding.
Saxena et al. (EMNLP 2024) is the closest precursor to our shaped cache experiment in their "Eigen Attention" work. They compute principal basis vectors via SVD on calibration data and perform attention in a low-rank subspace, achieving up to 40% KV cache reduction. The key difference is that they apply low-rank approximation to both keys and values with a shared error threshold and require fine-tuning to recover quality, while our experiment separately calibrates key and value eigenbases, revealing that the quality threshold differs dramatically between the two.
DynaKV (2026) takes a different angle by learning a per-token gating mechanism that dynamically chooses how many dimensions to retain, rather than using fixed truncation. At 20% retention on Llama-3-8B, DynaKV achieves 62% average accuracy where fixed low-rank methods drop to 45 to 48%, though it requires post-training with 128M tokens.
ReCalKV (Yan et al., 2025) and AsymKV (Cui & Xu, 2025) both confirm the asymmetry from their own perspectives: ReCalKV develops separate SVD strategies for keys versus values, while AsymKV discovers that adjacent keys are locally homogeneous but adjacent values are heterogeneous, building a compression framework around merging keys while preserving values.
What our shaped cache experiment adds to this body of work is the precise Pareto frontier. We now know exactly how many key dimensions (32, or 8x the d_eff) and value dimensions (96+) you need before truncation becomes viable, across three models and four quantization levels. And the answer is: by the time you retain enough dimensions for acceptable quality, you have barely compressed anything beyond what quantization alone would give you.
Implications
For KV cache compression research: The shaped cache result closes the door on dimension-reduction approaches. The multi-regime result opens a door on smarter bit allocation. The push-to-0.95 result clarifies what matters: value quantization after spectral rotation is the remaining bottleneck.
For understanding transformers: Key vectors are essentially binary selectors in the spectral basis. Their role in attention is to establish which positions to attend to, and this selection function requires only directional information (the sign of each spectral component), not magnitude precision. Value vectors are content carriers. Their reconstruction fidelity directly determines output quality, and they use a much larger fraction of the available dimensions.
For practitioners: Use multi-regime spectral quantization with 1-bit keys and 4 to 5 bit values. This gives 5 to 6x compression with quality comparable to the original SpectralQuant. For aggressive compression (7 to 8x), drop to 3-bit values and accept moderate quality loss. For memory-constrained settings, 1-bit everything at 14x is surprisingly usable.
Code and data: https://github.com/Dynamis-Labs/spectralquant
This is a follow-up to 3% Is All You Need: Breaking TurboQuant's Compression Limit via Spectral Structure. SpectralQuant grew out of the research program at Sentra, working on building enterprise general intelligence: a shared AI layer that sits on all communication channels and agent traces to understand how everyone in an organization actually works and how work actually gets done.