
TL;DR
The augmenting and replacement futures use the same models and the same tools. The thing that separates them is a design choice about where consequence lands.
The agent's real job isn't to do the work. It's to compress the world into the smallest faithful decision somebody can sign their name to. Everything else follows from getting that compression right.
That "somebody" needs a name on file. Generic accountability dissolves under load, so every consequential action has to trace back to a specific person who had a real chance to refuse it.
Permission fatigue pulls agentic systems toward replacement on its own gradient. The augmenting future has to be engineered against that pull rather than assumed.
If you build the agent and profit from its autonomy, you should carry the liability when that autonomy goes wrong. The defaults change on their own once the bill lands on the builder.
The market that follows from keeping a person on the hook is plausibly an order of magnitude larger than the "vertical agents replace half the jobs" story currently being funded, because it's anchored on the wage base of skilled labor rather than enterprise software budgets.

Claude Code ships a flag called `--dangerously-skip-permissions`. The naming is honest; the flag does what it says on the tin. An agent running with the flag enabled isn't more capable than one running without it; what changes is that a chain which used to route through a human now routes around them.
The flag is a confession. It admits that the same system, with identical capabilities underneath, can be run in a mode that augments a person or in a mode that quietly replaces them. The replacement mode doesn't require a different model; it requires the consent step out of the way.
That's the argument compressed. In the most capable agentic systems shipping today, much of the gap between augmentation and effective replacement comes from removing approval rather than from inventing a new capability class. Whether the next decade looks like a world of augmented humans or a world of autonomous agents acting on our behalf has less to do with model capability than with whether the people building these systems treat the human in the loop as the point of the system or as friction in it.
The question under every other question
Underneath every technical question is a non-technical one few want to ask out loud. Is AI for augmenting humans, or is AI itself the point?
The two answers imply genuinely different futures. Augmenting holds that the human is where value lives, and the agent's job is to make that human reach further and decide better. AI-as-point holds that intelligence in the world is where value lives, and the human is, eventually, an inefficient substrate for it. Most agentic products silently encode one position, and surprisingly few founders have been asked plainly which.
Both capability and consent design are still moving. This essay focuses on the consent side because it's the variable builders actually control today, and because the qualities that stay economically valuable after generation gets cheap are the ones you can't detach from a person: judgment, taste, relationships, accountability, the willingness to put a name on a decision and live with the consequences. Liability is the most concrete of those, and the only one with centuries of enforcement infrastructure already wired up to it.
The constraint: liability ends with somebody specific
The structural rule separating the augmenting future from the replacement future goes roughly like this. Every consequential action taken by an agent has to trace, through a recorded chain, back to a specific person who saw the relevant context and had a real chance to say no to it.
Generic accountability fails the test fast. "The company is responsible" covers nothing operationally. "The user clicked accept" accepts nothing in particular. "A human reviewed the workflow" allows that human to have reviewed something completely different from what eventually shipped. What's required is a person, with a name attached, who saw this decision in front of them, had the option to refuse, and chose otherwise.
This sounds bureaucratic until you notice the properties liability has that the alternatives don't. Capability gains can't optimize it away; a smarter model has no effect on who eventually gets sued, fined, or jailed. It forces the design surface to expose a refusal point. It scales naturally with stakes. And it's the strongest cross-domain constraint with enforcement infrastructure already in place: courts, insurers, professional boards, regulators. Licensing, fiduciary duty, and domain regulation all do real work, but they bind narrower surfaces and presuppose the liability question is already answered.
The alternatives at the AI layer don't survive the same tests. Alignment isn't enforceable; we can't even agree on what it means. Explainability can be satisfied in form without being satisfied in substance. "Human in the loop" has been hollowed out to mean "there's a person somewhere nearby." Liability has teeth because the infrastructure for enforcing it was built centuries before the technology arrived.
Permission fatigue is the gradient
The gradient pulls toward replacement, and it pulls hard. Each permission prompt costs attention. The agent is usually right. The expected value of approving without reading is positive on any single decision in isolation. So the rational user learns to approve faster, then in batches, then to flip auto-approve on for a class of action, then for several, then to enable the dangerous flag for the session, then to forget the flag was ever there.
I flipped the flag in my second week with Claude Code and stopped noticing by my third. Every developer I know who's lived inside Cursor or Devin for any length of time has the same story. The pattern shows up with cookie banners, EULAs, TLS warnings, and phone permission popups. Repeated low-stakes consent decisions converge toward unconditional consent. That's a property of cognition, not a moral failing.
An augmenting future doesn't happen on its own. The default trajectory of a naively designed agentic system is replacement, because the user themselves will request the replacement path one convenience at a time. The other future has to be engineered against the gradient.
The agent as press secretary
The valuable thing the agent does isn't the work. It's the compression that makes the work signable.
A frontier model can comfortably write a 4,000-line pull request, draft a 30-page contract, produce a clinical note, or place a trade. The bottleneck on any of those mattering isn't producing the artifact; it's the human's capacity to absorb the consequences once it ships. A pull request nobody understands becomes a liability the moment it merges. A contract nobody read becomes a time bomb the moment it's signed. A clinical note that no licensed clinician has actually attested to is, in most regulated medical settings, not a clinical note at all.
In the augmenting framing the agent does everything except the signature. Read the 10,000 pages of context. Draft the 4,000 lines of code. Compute the 30 reasonable alternatives. Then compress all of that into the smallest faithful representation a person needs in order to say yes or no with their own name on the bottom.
Think of the agent as a press secretary. The president signs; the press secretary makes the signature possible by doing the work that precedes it.
This is a harder engineering problem than doing the work autonomously. Artifact generation is advancing faster than faithful decision compression, and the winners of the augmenting market will be the ones producing the shortest faithful summaries for the highest-liability actions in their vertical.
The open problem inside that sentence is the word "faithful." A summary the human can absorb is only useful if its compression is honest about what it dropped. Whether you can verify that programmatically is the actual hard technical question of the augmenting future, and most of the field is barely engaging with it yet. The primitives are starting to appear: paraphrase tests that confirm the human's understanding matches the underlying artifact, dissent surfacing that forces minority alternatives into the summary, counterfactual probes ("what would the agent have done if you'd refused?"), and reproducibility checks that another agent can derive the same summary from the same context. None of these are solved. The teams that solve them first will have a moat that capability scaling won't erode.
A liability schema for actions
If liability is doing the structural work, then every action an agent can take needs to come with a liability class attached, and that class needs to determine the minimum signoff posture for the action. There isn't a widely adopted schema for this yet, and there probably should be.
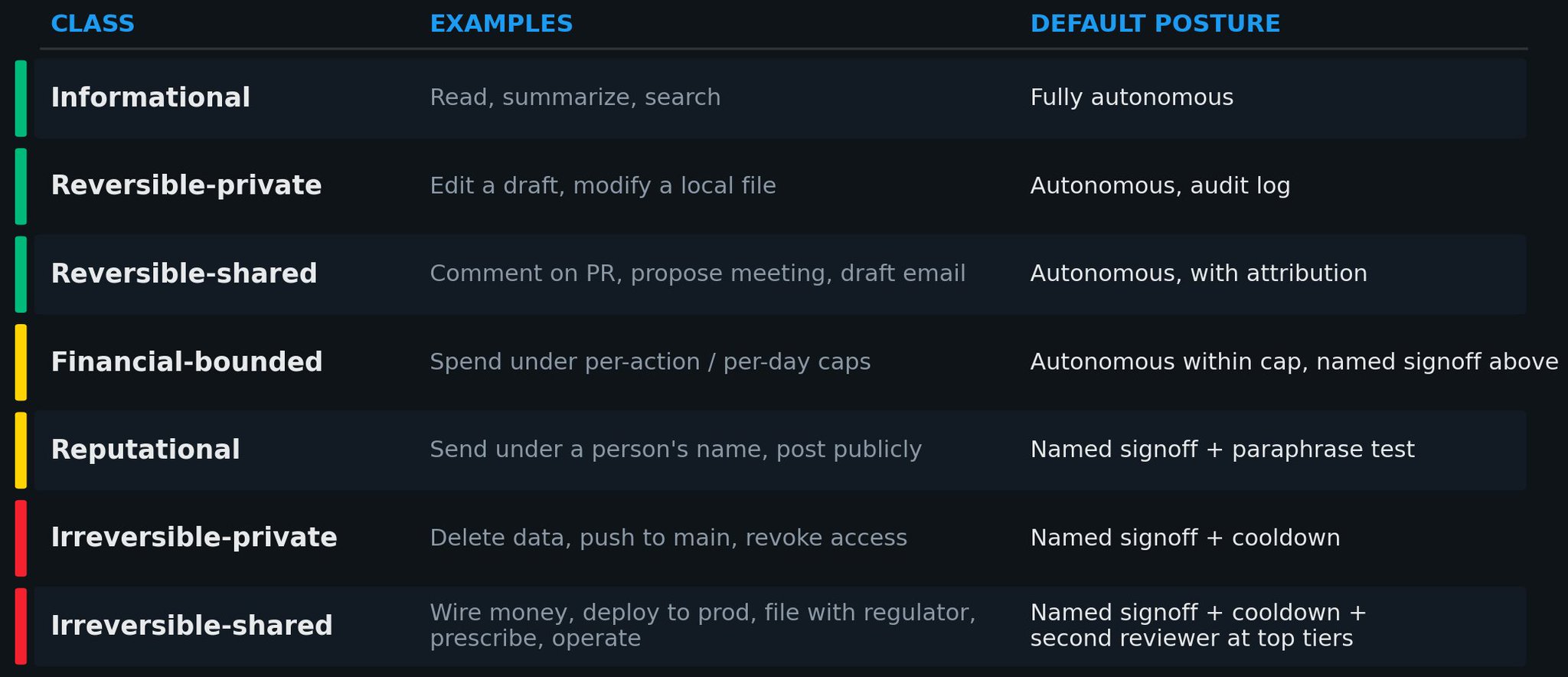
Posture matched to consequence is the only realistic way to manage permission fatigue. The top tiers add positive engagement requirements (a paraphrase test, a cooldown, a second reviewer) because the failure mode there is humans approving without thinking, not agents recommending the wrong thing.
Do you care?
Everything above sits downstream of one founder-level question: do you care about humans being part of this future at all? A lot of product decisions in agentic AI right now amount to a quiet vote on that question, cast by people who'd rather not admit they're voting on anything.
If you care, the design constraints follow with little ambiguity. You build the liability schema. You make refusal a first-class affordance. You measure on the quality of the summary the agent hands a person, not the autonomy of what it ships without one. You bind every consequential action to a specific person inside a tamper-evident log. The technical work here is real but tractable. Most of the difficulty is in wanting it, because the augmenting build makes demos less impressive and per-seat economics less aggressive than the alternative.
Anthropic is the cleanest example of how the category itself drifts, not because the lab is uniquely careless but because it's uniquely articulate about safety and so the gap between framework and surface area is easy to read. The Responsible Scaling Policy and the Constitutional AI work govern model behavior at training time. The autonomy defaults of the agent shipped on top of those models live in a different policy regime, and the convenience flag sits one keystroke away from the default in the agent layer. The same pattern shows up across most of the major coding agents; Anthropic just lets you see it most clearly. That's the Anthropic paradox: the lab that writes the clearest safety frameworks in the industry also ships the agent with the shortest path from augmentation to replacement, and the second fact is visible only because the first one is.
Credit where it's due: in March they shipped "auto mode," a middle path between manual approval and the dangerous flag, with a Sonnet 4.6 classifier reviewing each action before it runs. Their own announcement names the problem out loud as "approval fatigue" and reports that users accept 93% of manual prompts anyway, which is permission fatigue with a number attached to it. That diagnosis matches the one I'm making here.
The prescription is where I'd push further. Auto mode replaces the human approver with a model approver, which keeps the gradient running one level up rather than terminating it. The classifier blocks dangerous actions, but no specific person ends up on the hook for the ones it lets through. Anthropic itself acknowledges that auto mode "doesn't eliminate" the risk and recommends running it inside isolated environments, which is another way of saying the liability question is still open.
The obvious objection is that terminating at a person is what manual mode does, and manual mode is exactly what fatigue defeats. The reason builder-borne liability escapes its own gradient is that it changes who pays for over-approval. Under the current allocation, the user pays for every prompt they read carefully and the builder pays for none of them, so the builder ships defaults that minimize the user's friction and externalize the risk. Move the cost of an unreviewed action onto the builder and the calculus inverts: the builder now has a direct financial reason to design schemas, paraphrase tests, and posture tiers that make signoff cheap when stakes are low and expensive when stakes are high. The gradient doesn't disappear, it changes sign. That's the move I haven't seen a major lab take yet, including the one that came closest to naming why it matters.
If you build the agent, you carry the liability
If the explicit purpose of an agent is to take an action a human would otherwise have taken, the company that built and operates the agent should bear the same liability the human would have borne. The principle isn't radical. It already applies to every industry that ships things which act in the world: Toyota for its brakes, Boeing for its flight software, Pfizer for its drugs, the bridge engineer for the bridge, the doctor for the prescription. The pattern shows up in roughly every legal system on earth.
AI has so far enjoyed a quiet exemption. The model provider claims to be a tool vendor; the wrapper company claims to be a thin layer over the model; the user clicked an arbitration clause disclaiming everything in advance. When an agentic failure cascades (Air Canada's chatbot ruling, Replit wiping a production database, or any future incident in the shape of Knight Capital's 2012 trading malfunction that lost $440 million in 45 minutes), the bill lands on the user, the party least equipped to pay it. That allocation won't survive the first catastrophe that puts a real number on a real piece of paper.
The fix is simple to state. Whoever builds the agent and profits from its autonomy bears the consequences when that autonomy goes wrong. The moment that lands on the builder, permission prompts stop feeling like friction and start feeling like insurance. The dangerous flag gets renamed. The defaults change on their own.
Carrying your own liability is what separates a real industry from an extractive one.
Regulation as channeling
The market doesn't drift toward the augmenting future on its own. Regulators and underwriters do most of the channeling, and on balance that's fine.
Europe is the likely first regulatory channel. The EU has a track record (GDPR, the AI Act, the DMA) of writing rules the rest of the world complies with by default, because maintaining a separate non-EU product usually costs more than complying with the European version. A floor requiring consequential actions to terminate at a named human with a documented chance to refuse is closer to crash-test standards than to a brake on progress.
The more immediate forcing function is insurance. Underwriters writing E&O, D&O, and cyber policies have to decide what happens when an agent acts under a customer's credentials and causes a loss; the cleanest path to a payable claim is one with a named human in the chain, and premiums on policies without that structure will come to reflect the difference. Builders who'd rather write the schema themselves than let regulators or carriers write it for them have a narrow window.
The market story under the funded one
The dominant story claims vertical agents will absorb roughly half the jobs in any vertical they touch, with value consolidating into a handful of vertically integrated agent companies: an Anthropic of law, an Anthropic of medicine, an Anthropic of accounting. Some version of that thesis underwrites nearly every multi-billion-dollar AI funding round of the last eighteen months. It's the replacement framing wearing a business hat, and it's wrong about market structure in ways that matter for how capital should be deployed.
The augmenting framing implies a different shape. If every consequential action terminates at a person with a name, the unit being sold is the leveraged human, not the autonomous agent. The doctor reading three times as many cases at higher accuracy is the buyer. So is the lawyer covering ten times the deal flow, the engineer shipping at five times the velocity, the accountant, underwriter, analyst, architect, surgeon, teacher, loan officer, journalist, and pharmacist behind them.
That market is larger because it doesn't require consolidation, it requires distribution at scale. The right valuation anchor isn't enterprise software budgets but the wage base of the workers being leveraged. Global enterprise IT spend lives around $4T/year (Gartner). The global compensation bill for skilled, licensed, and knowledge-class work lives an order of magnitude above that, on the rough order of $40T/year, derived from the ILO's global labor income figures with the skilled share carved out. AI companies don't capture the full wage base; they capture some productivity share of it. But even single-digit-percent capture of $40T anchors a market on the order of all of enterprise software today, and that's the floor, not the ceiling. The size of the prize sits downstream of one design decision about where liability comes to rest.
The winners look more like tools than replacements, priced per leveraged human rather than per replaced job, integrated into existing professional workflows rather than disintermediating them. Thousands of them, not a handful. The eventual shape looks more like SaaS than cloud infrastructure. We're in the low single digits on the deployment curve, and the famous penetration chart everyone shares is three pixels on a graph that extends another decade to the right. The shape of those pixels is being set right now by a small set of design choices inside a small set of products.
The choice
Leaving the person on the hook forces the architecture to organize itself around augmenting them. Taking the person off lets it organize itself around replacement by default, even in cases where nobody in the room would have voted for that outcome if you'd asked them plainly.
The real question isn't whether some actions should be fully automated. The schema above admits as much: informational reads should be. The question is where the line moves as stakes climb, and who gets to move it. In many of the most capable agentic systems shipping today, the path from augmentation to effective replacement is alarmingly short, often a single flag or default. The work that matters is keeping that flag the dangerous one rather than letting convenience promote it into the default. If builders do that work themselves, we end up in the augmenting future without much drama. If not, regulators and underwriters do it for them, which turns out fine too.
Whether you care is the design choice. The answer determines what you build. The question every founder shipping an agent right now has to answer in public is the one few seem willing to: are you building augmentation, or are you building replacement?